-
chevron_right
Development blog for GNOME Shell and Mutter: Notifications in 46 and beyond
news.movim.eu / PlanetGnome · 13:01 · 10 minutes

One of the things we’re tackling as part of the
STF infrastructure initiative
is improving notifications. Other platforms have advanced significantly in this area over the past decade, while we still have more or less the same notifications we had since the early GNOME 3 days, both in terms of API and feature set. There’s plenty to do here

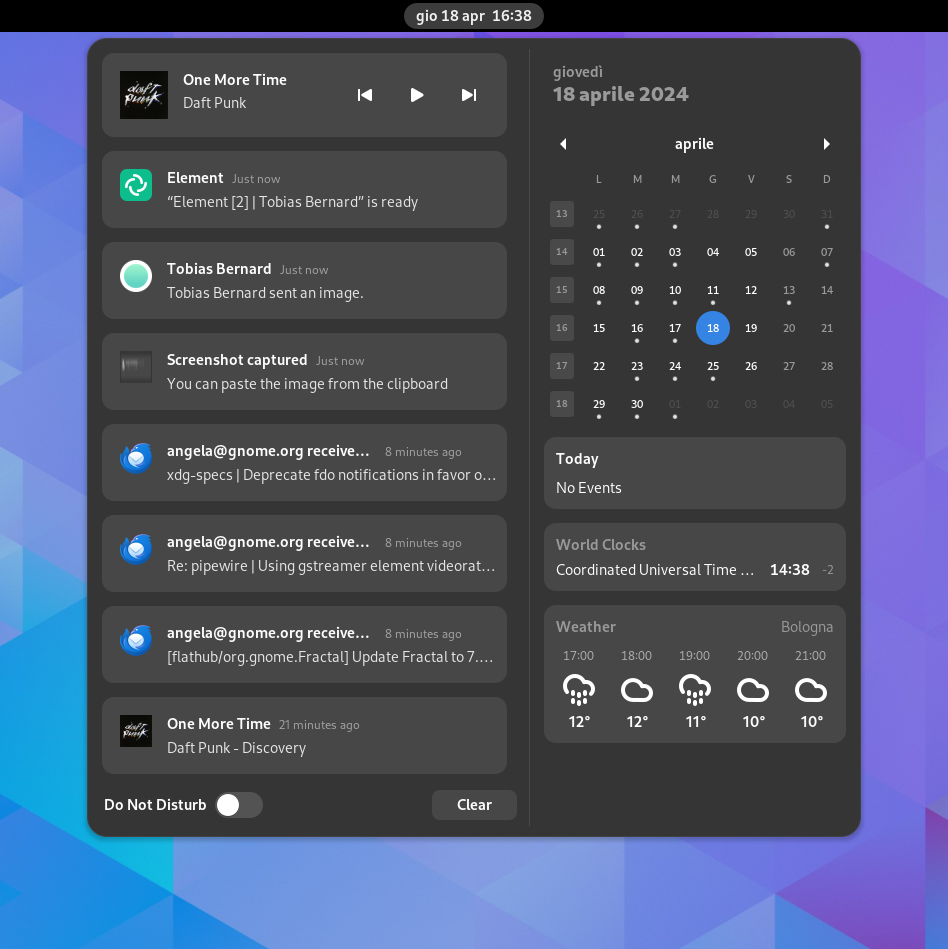 The notification drawer on GNOME 45
The notification drawer on GNOME 45
Modern needs
As part of the effort to port GNOME Shell to mobile Jonas looked into the delta between what we currently support and what we’d need for a more modern notification experience. Some of these limitations are specific to GNOME’s implementation, while others are relevant to all desktops.
Tie notifications to apps
As of GNOME 45 there’s no clear identification on notification bubbles which app they were sent by. Sometimes it’s hard to tell where a notification is coming from, which can be annoying when managing notifications in Settings. This also has potential security implications, since the lack of identification makes it trivial to impersonate other apps.
We want all notifications to be clearly identified as coming from a specific app.
Global notification sounds
GNOME Shell can’t play notification sounds in all cases, depending on the API the app is using (see below). Apps not primarily targeting GNOME Shell directly tend to play sounds themselves because they can’t rely on the system always doing it (it’s an optional feature of the XDG Notification API which different desktops handle differently). This works, but it’s messy for app developers because it’s hard to test and they have to implement a fallback sound played by the app. From a user perspective it’s annoying that you can’t always tell where sounds are coming from because they’re not necessarily tied to a notification bubble. There’s also no central place to manage the notification behavior and it doesn’t respect Do Not Disturb.
Notification grouping
Currently all notifications are just added to a single chronological list, which gets messy very quickly. In order to limit the length of the list we only keep the latest 3 notifications for every app, so notifications can disappear before you have a chance to act on them.
Other platforms solve this by grouping notifications by app, or even by message thread, but we don’t have anything like this at the moment.
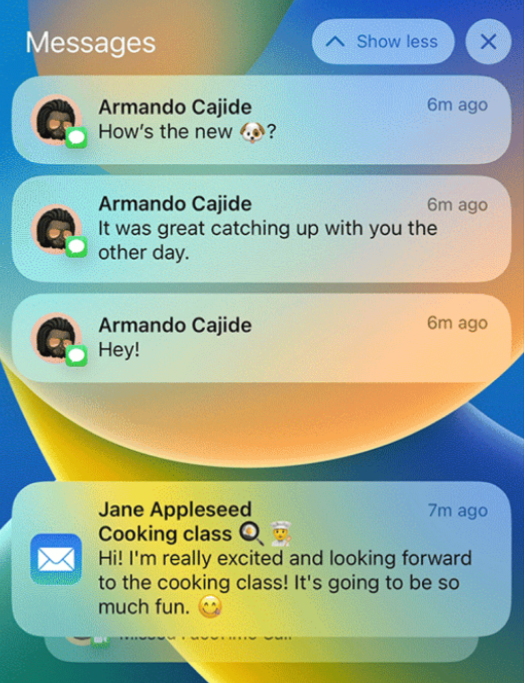 Notifications grouped by app on the iOS lock screen
Notifications grouped by app on the iOS lock screen
Expand media support
Currently each notification bubble can only contain one (small) image. It’s mostly used for user avatars (for messages, emails, and the like), but sometimes also for actual content (e.g. a thumbnail for the image someone sent).
Ideally what we want is to be able to show larger images in addition to avatars, as the actual content of the notification.
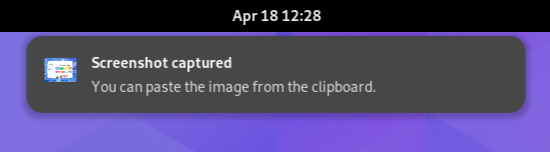 As of GNOME 45 we only have a single slot for images on notifications, and it’s too small for actual content.
As of GNOME 45 we only have a single slot for images on notifications, and it’s too small for actual content.
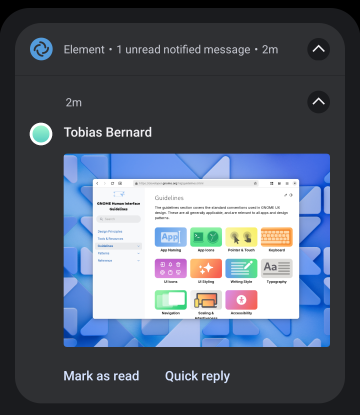 Other platforms have multiple slots (app icon, user avatar, and content image), and media can be expanded to much larger sizes.
Other platforms have multiple slots (app icon, user avatar, and content image), and media can be expanded to much larger sizes.
There’s also currently no way to include descriptive text for images in notifications, so they are inaccessible to screen readers. This isn’t as big a deal with the current icons since they’re small and mostly used for ornamental purposes, but will be important when we add larger images in the body.
Updating notification content
It’s not possible for apps to update the content inside notifications they sent earlier. This is needed to show progress bars in notifications, or updating the text if a chat message was modified.
How do we get there?
Unfortunately, it turns out that improving notifications is not just a matter of standardizing a few new features and implementing them in GNOME Shell. The way notifications work today has grown organically over the years and the status quo is messy. There are three different APIs used by apps today: XDG Notification , Gio.Notification , and XDG Portal .
XDG Notification
This is the Freedesktop specification for a DBus interface for apps to send notifications to the system. It’s the oldest notification API still in use. Other desktops mostly use this API, e.g. KDE’s KNotification implements this spec.
Somewhat confusingly, this standard has never actually been finalized and is still marked as a draft today, despite not having seen significant changes in the past decade.
Gio.Notification
This is an API in GLib/Gio to send notifications, so it’s only used by GTK apps. It abstracts over different OS notification APIs, primarily the XDG one mentioned above, a private GNOME Shell API , the portal API, and Cocoa (macOS).
The primary one being used is the private DBus interface with GNOME Shell. This API was introduced in the early GNOME 3 days because the XDG standard API was deemed too complicated and was missing some features (in particular notifications were not tied to a specific app).
When using Gio.Notification apps can’t know which backend is used, and how a notification will be displayed or behave. For example, notifications can only persist after the app is closed if the private GNOME Shell API is used. These differences are specific to GNOME Shell, since the private API is only implemented there.
XDG Portal
XDG portals are secure, standardized system APIs for the Linux desktop. They were introduced as part of the push for app sandboxing around Flatpak, but can (and should) be used by non-sandboxed apps as well.
The XDG notification portal is based on the private GNOME Shell API, with some additional features from the XDG API mixed in.
XDG portals consist of a frontend and a backend. In the case of the notification portal, apps talk to the frontend using the portal API, while the backend talks to the system notification API. Backends are specific to the desktop environment, e.g. GNOME or KDE. On GNOME, the backend uses the private GNOME Shell API when possible.
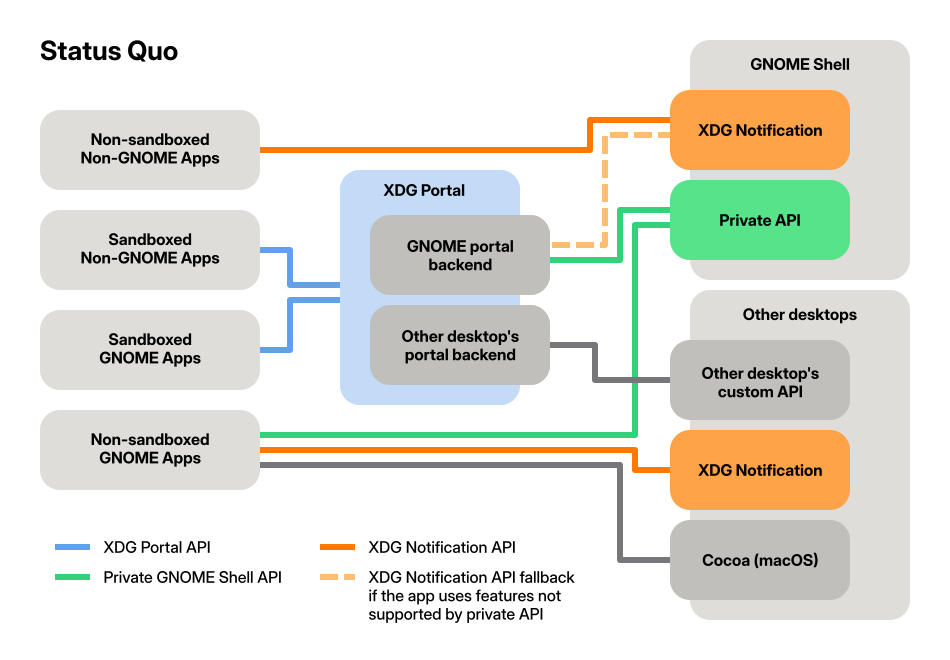 How different notification APIs are used today
How different notification APIs are used today
The plan
From the GNOME Shell side we have the XDG API (used by non-GNOME apps), and the private API (used via Gio.Notification by GNOME apps). From the app side we additionally have the XDG portal API. Neither of these can easily supersede the others, because they all have different feature sets and are widely used. This makes improving our notifications tricky, because it’s not obvious which of the APIs we should extend.
After several discussions over the past few months we now have consensus that it makes the most sense to invest in the XDG portal API. Portals are the future of system APIs on the free desktop, and enable app sandboxing. Neither of the other APIs can fill this role.
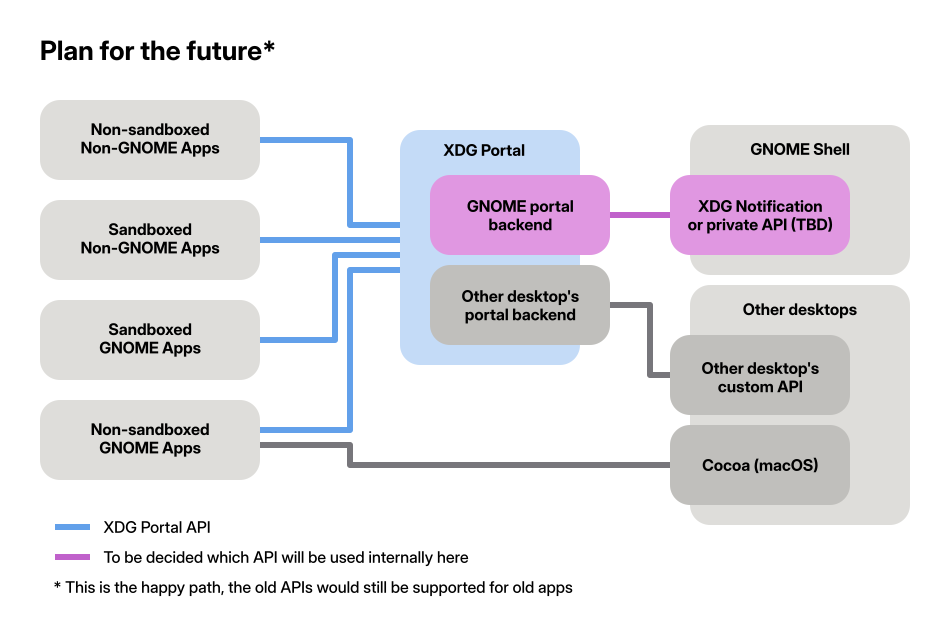 Our plan for notification APIs going forward: Focus on the portal API
Our plan for notification APIs going forward: Focus on the portal API
This requires work in a number of different modules, including the XDG portal spec, the XDG portal backend for GNOME, GNOME Shell, and client libraries such as Gio.Notification (in GLib), libportal , libnotify , and ashpd .
In the XDG portal spec, we are adding support for a number of missing features:
- Tying notifications to apps
- Grouping by message thread
- Larger images in the notification body
- Special notifications for e.g. calls and alarms
- Clearing up some instances of undefined behavior (e.g. markup in the body, playing sounds, whether to show notifications on the lock screen, etc.)
This is the draft XDG desktop portal proposal for the spec changes.
On the GNOME Shell side, these are the primary things we’re doing (some already done in 46):
- Cleanups and refactoring to make the code easier to work on
- Improve keyboard navigation and screen reader accessibility
- Header with app name and icon
- Show full notification body and buttons in the drawer
- Larger notification icons (e.g. user avatars on chat notifications)
- Group notifications from the same app as a stack
- Allow message threads to be grouped in a single notification bubbles
- Larger images in the notification body
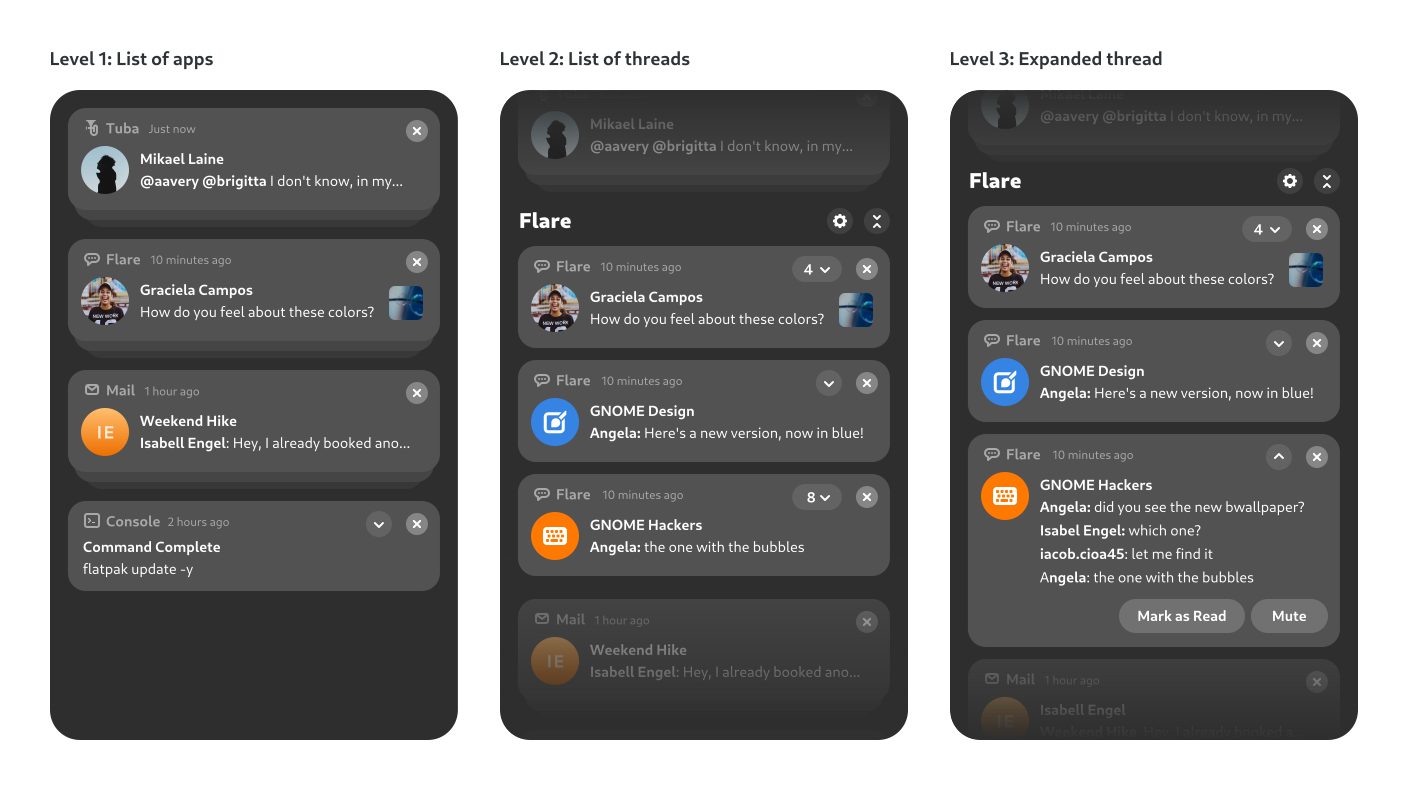 Mockups
of what we’d ideally want, including grouping by app, threading, etc.
Mockups
of what we’d ideally want, including grouping by app, threading, etc.
There are also animated mockups for some of this, courtesy of Jakub Steiner .
The long-term goal is for apps to switch to the portal API and deprecate both of the others as application-facing APIs. Internally we will still need something to communicate between the portal backend and GNOME Shell, but this isn’t public API so we’re much more flexible here. We might expand either the XDG API or the private GNOME Shell protocol for this purpose, but it has not been decided yet how we’ll do this.
What we did in GNOME 46
When we started the STF project late last year we thought we could just pull the trigger on a draft proposal Jonas for an API with the new capabilities needed for mobile. However, as we started discussing things in more detail we realized that this was the the wrong place to start. GNOME Shell already didn’t implement a number of features that are in the XDG notification spec, so standardizing new features was not the main blocker.
The code around notifications in GNOME Shell has grown historically and has seen multiple major UI redesigns since GNOME 3.0. Additional complexity comes from the fact that we try to avoid breaking extensions, which means it’s difficult to e.g. change function names or signatures. Over time this has resulted in technical debt, such as weird anachronistic structures and names. It was also not using many of the more recent GJS features which didn’t exist yet when this code was written originally.
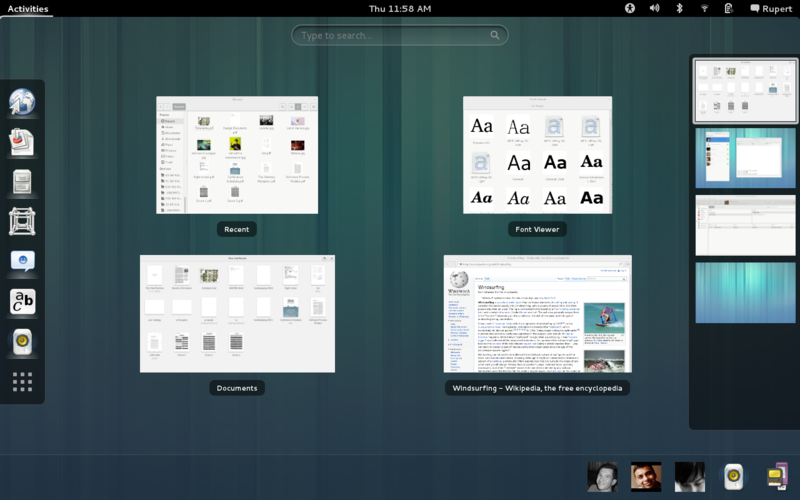 Anyone remember that notifications used to be on the bottom? This is what they looked like in GNOME 3.6 (2012).
Anyone remember that notifications used to be on the bottom? This is what they looked like in GNOME 3.6 (2012).
As a first step we restructured and cleaned up legacy code, ported it to the most recent GJS features, updated the coding style, and so on. This unfortunately means extensions need to be updated, but it puts us on much firmer ground for the future.
With this out of the way we added the first batch of features from our list above, namely adding notification headers , expanding notifications in the drawer, larger icons , and some style fixes to icons . We also fixed a very annoying issue with “App is ready” notifications not working as expected when clicking a notification ( !3198 and !3199 ).
We also worked on a few other things that didn’t make it in time for 46, most notably grouping notifications by app (which there’s a draft MR for), and additionally grouping them by thread (prototype only).
Throughout the cycle we also continued to discuss the portal spec , as mentioned above. There are MRs against against XDG desktop portal and the libportal client library implementing the spec changes. There’s also a draft implementation for the GTK portal backend .
Future work
With all the groundwork laid in GNOME 46 and the spec draft mostly ready we’re in a good position to continue iterating on notifications in 47 and beyond. In GNOME 47 we want to add some of the first newly spec’d features, in particular notification sounds, markup support in the body, and display hints (e.g. showing on the lock screen or not).
We also want to continue work on the UI to unlock even more improvements in the future. In particular, grouping by app will allow us to drop the “only keep 3 notifications per app” behavior and will generally make notifications easier to manage, e.g. allowing to dismiss all notifications from a given app. We’re also planning to work on improving keyboard navigation and ensuring all content is accessible to screen readers.
Due to the complex nature of the UI for grouping by app and the many moving parts with moving forward on the spec it’s unclear if we’ll be able to do more than this in the scope of STF and within the 47 cycle. This means that additional features that require the new spec and/or lots of UI work, such as grouping by thread and custom UI for call or alarm notifications will probably be 48+ material.
Conclusion
As we hope this post has illustrated, notifications are way more complex than they might appear. Improving them requires untangling decades of legacy stuff across many different components, coordinating with other projects, and engaging with standards bodies. That complexity has made this hard to work on for volunteers, and there has not been any recent corporate interest in the area, which is why it has been stagnant for some time.
The
Sovereign Tech Fund
investment has allowed us to take the time to properly work through the problem, clean up technical debt, and make a plan for the future. We hope to leverage this momentum over the coming releases, for a best-in-class notification experience on the free desktop. Stay tuned














{kind=link}