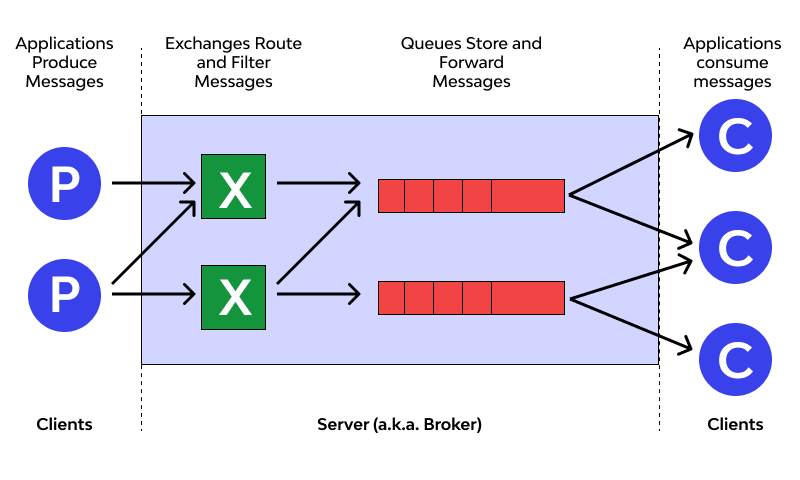
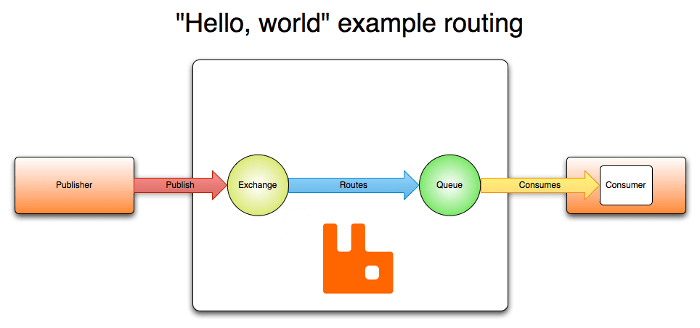
-
chevron_right
Erlang Solutions: Blockchain Tech Deep Dive | Innovating with Erlang and Elixir
news.movim.eu / PlanetJabber · 6 days ago - 09:10 · 7 minutes
We’re back with the latest in our Blockchain series, where we explore in-depth In our first post, we explored the Six Key Principles of Blockchain .
In our latest post, we’re making the case for using Erlang,Elixir and the BEAMVM to power your blockchain project.
Blockchain and business needs
Building a robust and scalable blockchain presents many challenges that a research and development team typically needs to address. The often ambitious goals to drive decentralised consensus and governance require unconventional approaches to achieve extra performance and reliability.
Improved Transactions per Second (TPS) is the most common challenge that blockchain-related use cases expose. TPS as the name suggests, is a metric that indicates how quickly a network can execute transactions per second. It is inherently difficult to produce a distributed peer-to-peer (P2P) network that can register transactions into a single data structure.
Guaranteeing consensus while delivering high TPS throughput among a vast number of nodes active on the network is even more challenging. Also, the fact that most public blockchains need to operate in a non-trusted mode requires adequate mechanisms for validation, which implies that contextual data needs to be available on demand. A blockchain should also be able to respond to anomalies such as network connectivity loss, node failure and malicious actors.
All of the above is further complicated by the continuous growth of the blockchain data structure itself, which becomes problematic in terms of storage.
It is clear that, unless businesses are prepared to invest vast amounts of resources, they would benefit from a high-level language and technology that allows them to quickly prototype and amend their code.
The ideal technology should also:
- Offer a strong network and concurrent capabilities
- Have technology built with distribution in mind
- Offer a friendly paradigm for asynchronous computation
- Not collapse under heavy load
- Deliver when traffic exceeds capacity
The Erlang Beam VM (available also in the Elixir syntax) undoubtedly scores high on the above list of desirable features.
Erlang & Elixir’s strengths for blockchain
Fast development
The challenge: Blockchain technology is present in extremely competitive markets. According to Grandview Marketing Analysis report, The global blockchain technology market size was valued at USD 17.46 billion in 2023 and is expected to grow at a compound annual growth rate (CAGR) of 87.7% from 2023 to 2030.
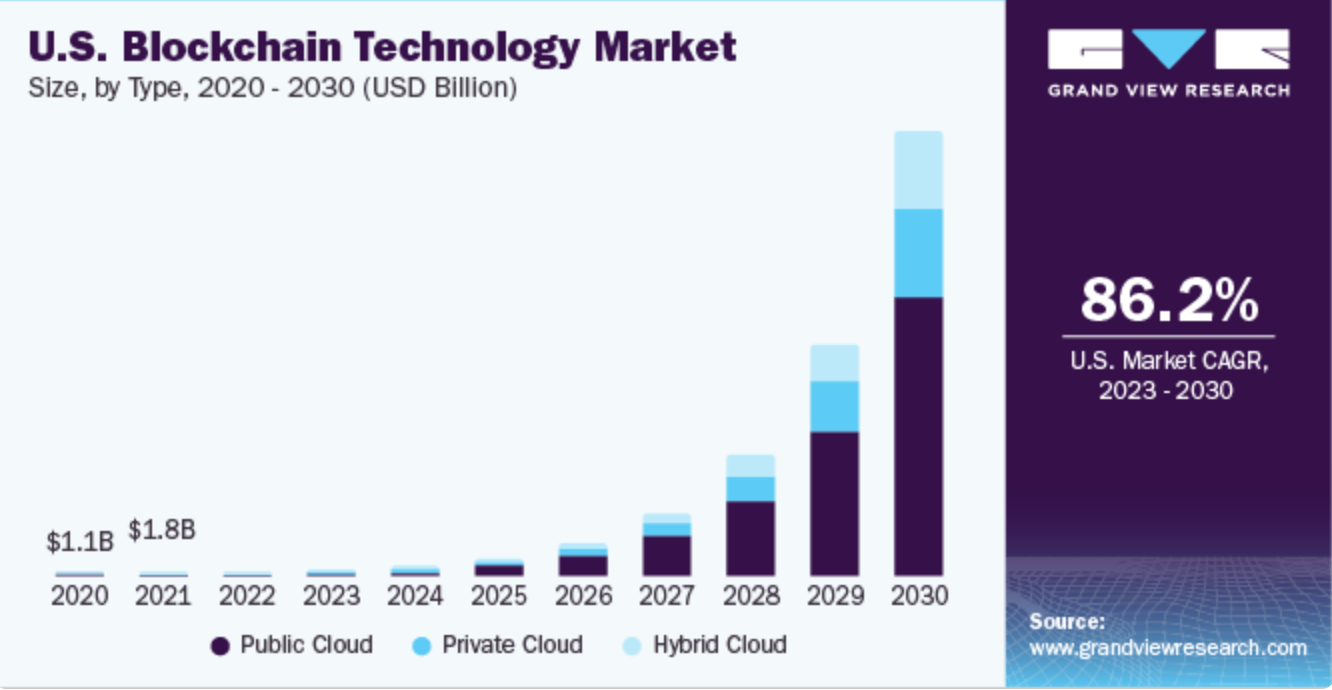
Grandview Marketing Analysis report
It is critical for organisations operating in them to be able to release new features in time to attract new customers and retain existing ones.
The answer: Both Erlang and Elixir are functional languages, operating at a very high level of abstraction which is ideal for fast prototyping and development of new ideas. By using these languages on top of the Beam VM, developers dramatically increase the speed to market when compared to other lower-level or object-oriented technologies.
Solutions developed in Erlang or Elixir also lead to a significantly smaller code base, which is easier to test and adapt to changes of direction. This is helpful when you proceed to fast prototyping new solutions and when you discover that amendments and upgrades are necessary, which is very typical in blockchain R&D activity. Both languages offer support for unit testing in their standard library. This enables developers to adopt Test Driven approaches ensuring the quality is preserved when modules and libraries get refactored. The common test framework also provides support for distributed tests and can be integrated with Continuous Integration frameworks like Jenkins . Both Erlang and Elixir shells let the programmer flesh out ideas fast and access running nodes for inspection.
Introspection
The challenge: To keep a competitive advantage in a fast-changing market, it is critical for organisations to promptly identify issues and opportunities by extracting relevant information about their running systems so that actions can be taken to upgrade them where appropriate.
The answer: Erlang and Elixir allow connection to an already running system and a status check. This is an extremely useful debugging tool, both in the development and production environment. Statuses of processes can be checked, and deadlocks in the live system can be analysed. Some various metrics and tools can show overload, bottlenecks and other key performance indicators. Enhanced introspection tools such as Erlang Solutions’ Wombat OAM are also helping with the identification of scalability issues when you run performance tests.

Networking
The challenge: Delivering a highly scalable and distributed P2P network is critical for blockchain enterprises. It is important to rely on stable battle-proven network libraries as reliable building blocks for exploiting use case-specific innovative approaches.
The answer: Erlang and Elixir come with strong and easy-to-manage network capabilities. There is a proven record of successful enterprises that rely on the BEAM VM’s networking strengths; including Adroll, WhatsApp, Bleacher Report , Klarna, Bet365 and Ericsson. Most of their use cases have strong analogies with the P2P networking that is required to deliver a distributed blockchain.
Combined with massive concurrency, the networking makes Erlang and Elixir ideal for server applications and means it can handle many clients. The binary and bitstring syntax makes parsing binary protocols particularly easy.
Massively concurrent
The challenge: There is a weakness afflicting Bitcoin and Ethereum where the computation of a block is competitive rather than collaborative. There is the opportunity to drive a collaborative concurrent approach: i.e. via sharding so that each actor can compute a portion of a block.
The answer: The BEAM VM powering Erlang and Elixir provides lightweight processes for applications. These are lightweight so that hundreds of thousands of them can run simultaneously. These processes do not share memory, communication is done over asynchronous messages (unlike goroutines) so there’s no need to synchronise them. The BEAM VM implementation also makes use of all of the available CPUs and cores. This makes Erlang and Elixir ideal for workloads that involve a huge amount of concurrency and consist of mostly independent workflows. This feature is especially useful in addressing the coordinated distribution of portions of work to compute a Merkle Tree of transactions.
High availability and resilience
The challenge: These are the requirements for every type of application and even more so for competitive and highly distributed blockchain networks. The communication and preservation of a state need to be as available as possible to avoid inconsistent states, network forks and disruptions experienced by the users.
The answer: The fault tolerance properties mentioned in the previous paragraph combined with built-in distribution leads to high availability even in cases of hardware malfunction. Erlang and Elixir have the built-in mnesia database system with the ability to replicate data over a cluster of nodes so if one node goes down, the state of the system is not lost.
Erlang and Elixir provide the supervisor pattern to handle errors.
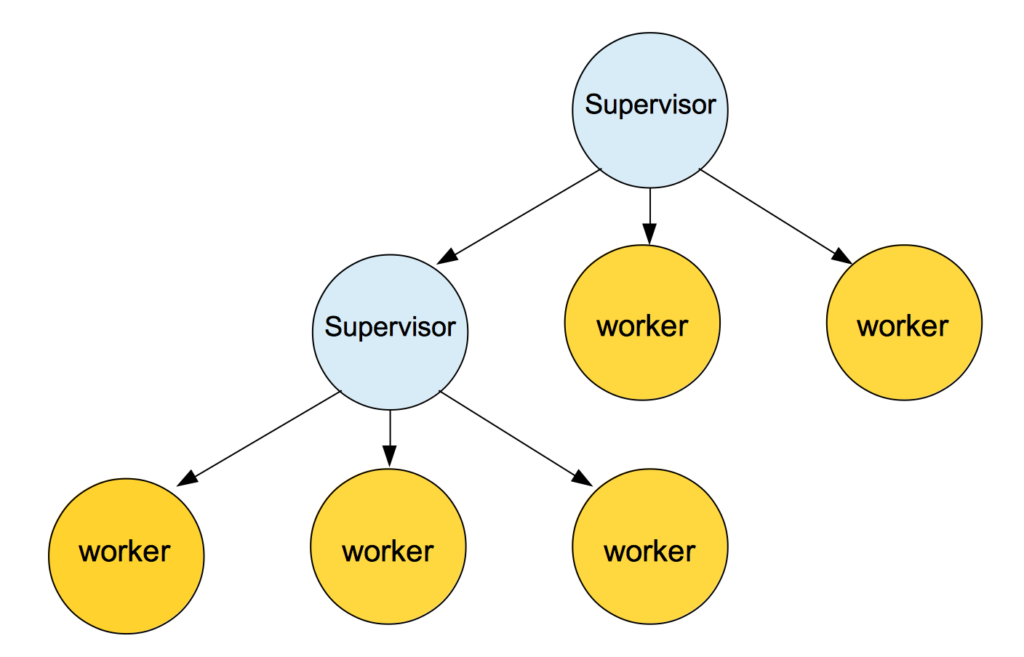
An example of a Supervision Tree , used to build a hierarchical process structure
Computing is done in multiple processes and if an error occurs and a process crashes, the supervisor is there to handle the situation, restart the computing or take some other measures. This pattern lets the actual code be cleaned as error handling can be implemented elsewhere. As processes are isolated, they do not share memory meaning errors are localised.
Built-in distribution
The challenge: This is highly relevant for trusted or hybrid networks where a central network takes authoritative decisions on top of a broader P2P network. Using the “out of the box” Erlang distribution and proven consistency approaches such as RAFT can be a quick win towards a fast prototype of a blockchain solution.
The answer: Erlang and Elixir provide out-of-the-box tools to run a distributed system. The message-handling functionalities of the system are transparent, so sending a message to a remote process is just as simple as sending it to a local process. There’s no need for convoluted IDLs, naming services or brokers.
Safety and Security
The challenge: Among the security features that both trusted and untrusted blockchain solutions strongly require, is the critical protection of access to the state memory, therefore reducing the exposure to a range of vulnerabilities.
The answer: Erlang and Elixir, just like many high-level languages, do not manipulate memory directly so applications written in Erlang and Elixir are effectively immune to many vulnerabilities like buffer overflows and return-oriented programming. Exploiting these vulnerabilities would require direct access to the memory, but the BEAM VM hides the memory from the application code.
While many business leaders are still trying to figure out how to put the technology to work for maximum ROI, most agree on two things:
- Blockchain unlocks vast value potential from optimised business operations.
- It’s here to stay.
Unlocking the potential of technology
Talking about blockchain implementation is no longer merely food for thought. Organisations should keep an eye on developments in blockchain tech and start planning how to best use this transformative technology, to unleash trapped value in key operational processes.
It’s clear – blockchain should be on every company’s agenda, regardless of industry.
If you want to start a conversation about engaging us for your project. Just drop the team a line.
The post Blockchain Tech Deep Dive | Innovating with Erlang and Elixir appeared first on Erlang Solutions .