-
 chevron_right
chevron_right
Nvidia : vers une nouvelle flambée des prix des cartes graphiques ?
news.movim.eu / JournalDuGeek · Monday, 8 April - 14:22

 chevron_right
chevron_right
Nvidia : vers une nouvelle flambée des prix des cartes graphiques ?
news.movim.eu / JournalDuGeek · Monday, 8 April - 14:22
 chevron_right
chevron_right
Geohot atomise les firmwares AMD et ça fait mal
news.movim.eu / Korben · Monday, 25 March - 17:40 · 2 minutes
![]()
Je sais pas si vous avez vu passer ça, mais dernièrement, il y a eu un peu de grabuge entre George Hotz (Geohot) et AMD, puisque ce dernier a essayé de faire tourner son framework IA Tiny Grad sur des GPU AMD .
Sauf que voilà, AMD lui a donné du fil à retordre avec ses firmwares propriétaires . Le driver open-source d’AMD se révélant être une jolie mascarade puisque tout les morceaux de code critiques sont bien protégés et sous licence.
Pourtant, Geohot n’a pas lésiné. Des mois à éplucher le code, à bypasser la stack logicielle, à discuter avec les pontes d’AMD. Mais rien à faire, les mecs veulent pas cracher leurs précieux blobs binaires . « Trop risqué, pas assez de ROI, faut voir avec les avocats. » Bref, c’est mort.
Pendant ce temps, Nvidia se frotte les mains avec son écosystème IA bien huilé. Des pilotes certifiés, des perfs au rendez-vous, une bonne communauté de devs… Tout roule pour eux, alors qu’AMD continue de s’enfoncer dans sa logique propriétaire , au détriment de ses utilisateurs.
La goutte d’eau pour Geohot ? Un « conseil » de trop de la part d’AMD qui l’a incité à « lâcher l’affaire « . Résultat, geohot est passé en mode « j e vais vous montrer qui c’est le patron « . Si AMD ne veut pas jouer le jeu de l’open-source , alors il va leur exposer leurs bugs de sécu à la face du monde !
Et c’est ce qu’il a fait puisque durant un live de plus de 8h, il s’est attaché à trouver plusieurs exploit dans le firmware des GPU AMD. Il est fort !
Dans l’IA, l’aspect hardware compte évidemment mais le software c’est le nerf de la guerre . Les boîtes noires, les firmwares buggés, le code legacy, c’est plus possible et les sociétés qui tournent le dos à la communauté des développeurs et des hackers font, selon moi, le mauvais choix.
Et ce qui arrive à AMD n’est qu’un exemple de plus.
Bref, comme d’habitude, gros respect à Geohot pour son combat de vouloir encore et toujours que la technologie profite au plus grand nombre. En attendant, suite à sa mésaventure avec AMD, il a annoncé qu’il switchait tout son labo sur du matos Nvidia et qu’il bazardait ses 72 Radeon 7900 XTX sur eBay. Si vous voulez des GPU d’occase pour pas cher (et apprendre à les faire planter ^^), c’est le moment !
Et si le code source de ses exploits vous intéresse, tout est sur Github .
Merci George !
Nvidia imagine bouleverser la modélisation 3D
news.movim.eu / Numerama · Friday, 22 March - 11:23

Demain, serons-nous tous modélisateurs 3D ? Nvidia a dévoilé une IA générative, appelée LATTE3D, qui transforme en instant du texte en des représentations 3D. La démonstration s'est focalisée sur des objets et des animaux, mais l'outil pourrait générer en 3D n'importe quoi.
 chevron_right
chevron_right
AMD promises big upscaling improvements and a future-proof API in FSR 3.1
news.movim.eu / ArsTechnica · Thursday, 21 March - 17:20

Enlarge (credit: AMD)
Last summer, AMD debuted the latest version of its FidelityFX Super Resolution (FSR) upscaling technology . While version 2.x focused mostly on making lower-resolution images look better at higher resolutions, version 3.0 focused on AMD's "Fluid Motion Frames," which attempt to boost FPS by generating interpolated frames to insert between the ones that your GPU is actually rendering.
Today, the company is announcing FSR 3.1 , which among other improvements decouples the upscaling improvements in FSR 3.x from the Fluid Motion Frames feature. FSR 3.1 will be available "later this year" in games whose developers choose to implement it.
Fluid Motion Frames and Nvidia's equivalent DLSS Frame Generation usually work best when a game is already running at a high frame rate, and even then can be more prone to mistakes and odd visual artifacts than regular FSR or DLSS upscaling. FSR 3.0 was an all-or-nothing proposition, but version 3.1 should let you pick and choose what features you want to enable.
chevron_right
WebGPU – Des failles qui permettent de siphonner les données des internautes avec un simple JS
news.movim.eu / Korben · Wednesday, 20 March - 07:29 · 2 minutes

Vous pensiez que votre GPU était à l’abri des regards indiscrets ? Que nenni damoiseaux zé demoiselles !!!
Une équipe de chercheurs vient de mettre en lumière des failles béantes dans la sécurité de l’API WebGPU , cette technologie qui booste les performances graphiques de nos navigateurs.
D’après cette étude , ces vulnérabilités permettraient à des scripts malveillants d’exploiter les canaux auxiliaires du GPU pour siphonner des données sensibles, comme vos mots de passe ou vos clés de chiffrement. Rien que ça ! 😱 Concrètement, les chercheurs ont réussi à monter ces attaques par canaux auxiliaires en fonction du temps et de l’état du cache du GPU, le tout depuis un simple navigateur web.
En analysant finement l’impact de différentes charges de travail sur les performances du processeur graphique, ils sont parvenus à en déduire des informations sur les autres processus utilisant cette ressource qui est, vous vous en doutez, partagée. Et c’est là qu’est le problème.
Le plus inquiétant, c’est que leur proof of concept se résume à du code JavaScript tout ce qu’il y a de plus basique. Pas besoin d’avoir accès au PC, un site web malveillant peut très bien faire l’affaire. De quoi donner des sueurs froides aux éditeurs de navigateurs… Rassurez-vous, je ne compte pas l’intégrer sur Korben.info, la bouffe n’est pas assez bonne en prison ^^.
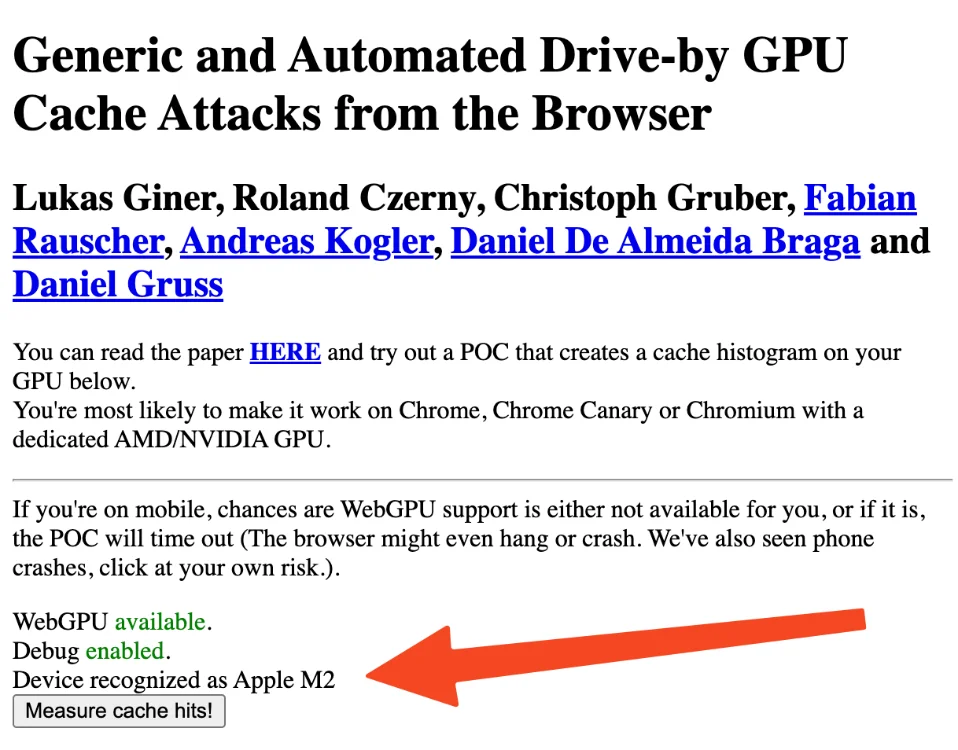
Pour l’instant, à part Mozilla qui a publié un bulletin d’avertissement , les principaux acteurs comme Google ou Microsoft n’ont pas réagi. Bouuuuh ! Ils estiment sans doute que le jeu n’en vaut pas la chandelle et préfèrent miser sur les gains de performances de WebGPU plutôt que de s’embarrasser avec des demandes d’autorisations qui gâcheraient l’expérience utilisateur.
Pourtant, les chercheurs sont formels, les sociétés qui conçoivent des navigateurs doivent traiter l’accès au GPU avec la même rigueur que les autres ressources sensibles comme la caméra ou le micro. Sinon, gare aux dérives ! On peut imaginer des utilisateurs qui se font piller leurs cryptomonnaies pendant qu’ils surfent innocemment, ou pire, des fuites de données à grande échelle orchestrées depuis des sites en apparence légitimes.
Avec ça, le bandeau RGPD peut aller se rhabiller ^^/
Rassurez-vous, pour le moment, WebGPU est activé par défaut uniquement dans Chrome et ses dérivés. Pour Firefox, c’est encore seulement dans les versions Nightly (mais ça arrive bientôt). Je vous laisse tester votre navigateur avec le proof of concept dont je vous parlais un peu plus haut.
Bref, cette étude a le mérite de lancer le débat sur les implications sécuritaires des API web de plus en plus intrusives. À l’heure où le GPU s’impose comme une ressource de calcul incontournable, y compris pour des tâches sensibles, la question de son isolation et de la maîtrise des accès devient cruciale.
Bref, on réfléchira à deux fois avant d’autoriser l’accès au GPU sur un site louche… 😉
chevron_right
Nvidia unveils Blackwell B200, the “world’s most powerful chip” designed for AI
news.movim.eu / ArsTechnica · Tuesday, 19 March - 15:27 · 1 minute

Enlarge / The GB200 "superchip" covered with a fanciful blue explosion that suggests computational power bursting forth from within. The chip does not actually glow blue in reality. (credit: Nvidia / Benj Edwards)
On Monday, Nvidia unveiled the Blackwell B200 tensor core chip—the company's most powerful single-chip GPU, with 208 billion transistors—which Nvidia claims can reduce AI inference operating costs (such as running ChatGPT ) and energy consumption by up to 25 times compared to the H100 . The company also unveiled the GB200, a "superchip" that combines two B200 chips and a Grace CPU for even more performance.
The news came as part of Nvidia's annual GTC conference, which is taking place this week at the San Jose Convention Center. Nvidia CEO Jensen Huang delivered the keynote Monday afternoon. "We need bigger GPUs," Huang said during his keynote. The Blackwell platform will allow the training of trillion-parameter AI models that will make today's generative AI models look rudimentary in comparison, he said. For reference, OpenAI's GPT-3, launched in 2020, included 175 billion parameters. Parameter count is a rough indicator of AI model complexity.
Nvidia named the Blackwell architecture after David Harold Blackwell , a mathematician who specialized in game theory and statistics and was the first Black scholar inducted into the National Academy of Sciences. The platform introduces six technologies for accelerated computing, including a second-generation Transformer Engine, fifth-generation NVLink, RAS Engine, secure AI capabilities, and a decompression engine for accelerated database queries.
Avec Blackwell, Nvidia améliore un facteur critique pour le futur de l’IA
news.movim.eu / Numerama · Tuesday, 19 March - 14:13

À l'occasion de sa conférence GTC, Nvidia a levé la voile sur la puce Blackwell B200, un nouveau GPU qu'il présente comme une « super puce ». Avec 208 milliards de transistors et une consommation énergétique en baisse, la puce Blackwell est la nouvelle arme fatale pour les acteurs de l'intelligence artificielle générative.
chevron_right
Review: AMD Radeon RX 7900 GRE GPU doesn’t quite earn its “7900” label
news.movim.eu / ArsTechnica · Wednesday, 28 February - 12:00

Enlarge / ASRock's take on AMD's Radeon RX 7900 GRE. (credit: Andrew Cunningham)
In July 2023, AMD released a new GPU called the "Radeon RX 7900 GRE" in China. GRE stands for "Golden Rabbit Edition," a reference to the Chinese zodiac, and while the card was available outside of China in a handful of pre-built OEM systems, AMD didn't make it widely available at retail.
That changes today—AMD is launching the RX 7900 GRE at US retail for a suggested starting price of $549. This throws it right into the middle of the busy upper-mid-range graphics card market, where it will compete with Nvidia's $549 RTX 4070 and the $599 RTX 4070 Super, as well as AMD's own $500 Radeon RX 7800 XT.
We've run our typical set of GPU tests on the 7900 GRE to see how it stacks up to the cards AMD and Nvidia are already offering. Is it worth buying a new card relatively late in this GPU generation, when rumors point to new next-gen GPUs from Nvidia, AMD, and Intel before the end of the year? Can the "Golden Rabbit Edition" still offer a good value, even though it's currently the year of the dragon?
chevron_right
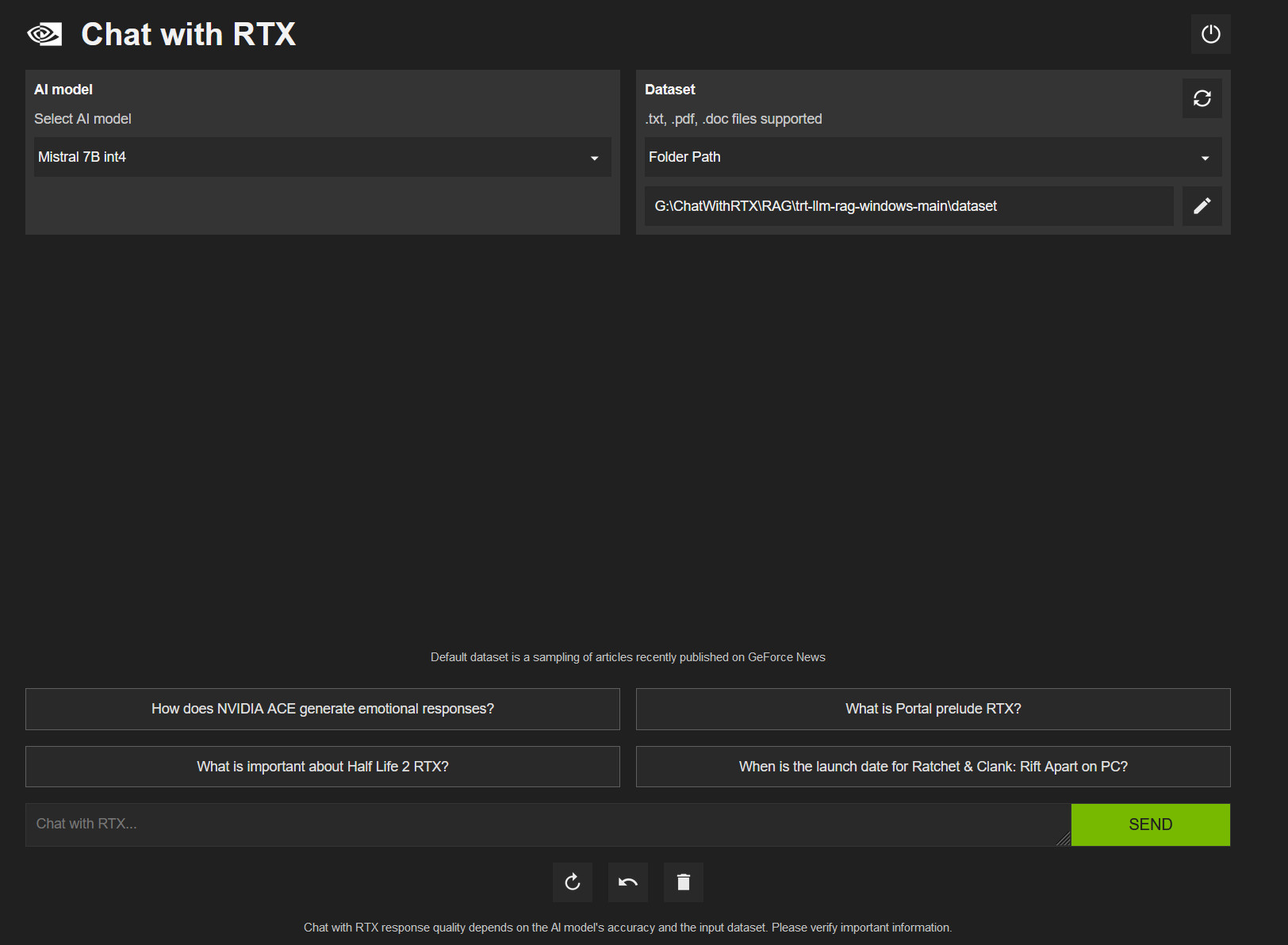
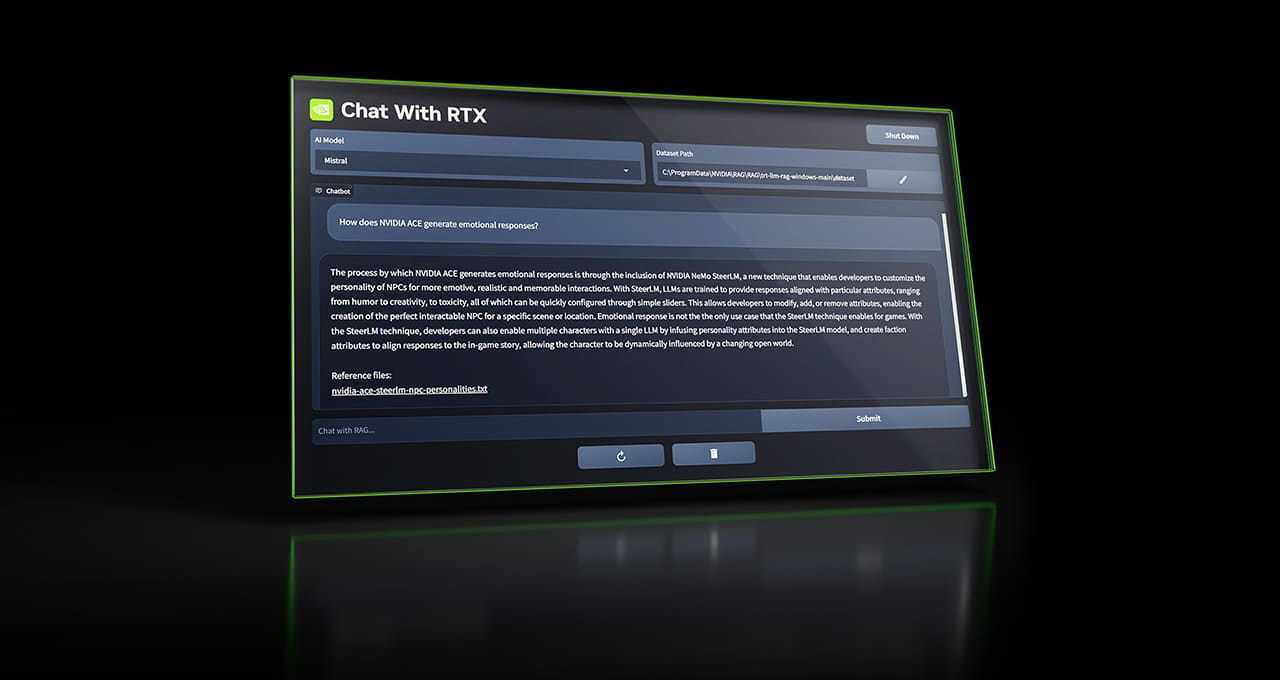
Nvidia’s “Chat With RTX” is a ChatGPT-style app that runs on your own GPU
news.movim.eu / ArsTechnica · Thursday, 15 February - 16:54 · 2 minutes

Enlarge (credit: Nvidia)
On Tuesday, Nvidia released Chat With RTX, a free personalized AI chatbot similar to ChatGPT that can run locally on a PC with an Nvidia RTX graphics card. It uses Mistral or Llama open-weights LLMs and can search through local files and answer questions about them.
Also, the application supports a variety of file formats, including .TXT, .PDF, .DOCX, and .XML. Users can direct the tool to browse specific folders, which Chat With RTX then scans to answer queries quickly. It even allows for the incorporation of information from YouTube videos and playlists, offering a way to include external content in its database of knowledge (in the form of embeddings) without requiring an Internet connection to process queries.
We downloaded and ran Chat With RTX to test it out. The download file is huge, at around 35 gigabytes, owing to the Mistral and Llama LLM weights files being included in the distribution. ("Weights" are the actual neural network files containing the values that represent data learned during the AI training process.) When installing, Chat With RTX downloads even more files, and it executes in a console window using Python with an interface that pops up in a web browser window.
Several times during our tests on an RTX 3060 with 12GB of VRAM, Chat With RTX crashed. Like open source LLM interfaces, Chat With RTX is a mess of layered dependencies, relying on Python, CUDA, TensorRT, and others. Nvidia hasn't cracked the code for making the installation sleek and non-brittle. It's a rough-around-the-edges solution that feels very much like an Nvidia skin over other local LLM interfaces (such as GPT4ALL ). Even so, it's notable that this capability is officially coming directly from Nvidia.
On the bright side (a massive bright side), local processing capability emphasizes user privacy, as sensitive data does not need to be transmitted to cloud-based services (such as with ChatGPT). Using Mistral 7B feels slightly less capable than ChatGPT-3.5 (the free version of ChatGPT), which is still remarkable for a local LLM running on a consumer GPU. It's not a true ChatGPT replacement yet, and it can't touch GPT-4 Turbo or Google Gemini Pro/Ultra in processing capability.
Nvidia GPU owners can download Chat With RTX for free on the Nvidia website.
{kind=link}
{kind=link}
{kind=link}
{kind=link}