Whether it is carpentry, auto mechanics, electrical engineering, or computer science, you always hear the same saying: use the right tool for the right job. The wrong tool can make any solution difficult and could introduce new problems.
I've previously written about some of the
big
problems
with the C2PA solution for recording provenance and authenticity in media. However, I recently came across a new problem based on their decision to use X.509 certificates and how they are used. Specifically: their certificates expire. This has some serious implications for authentication and legal cases that try to use C2PA metadata as evidence.
X.509 Background
Whether it's HTTPS or digital signatures, the terms "certificates", "X.509", and "x509" are often used interchangeably. While there are different types of digital certificates, most use the X.509 format. The name "X.509" refers to a section in the ITU standards. The different parts in the standard are called "Series". There are Series A, D, E, F, ... all the way to Z. (I don't know why they skipped B or C.) Series A covers their organization. Series H specifies audiovisual and multimedia systems.
Series X
covers data networks and related security. Within Series X, there are currently 1,819 different sections. "X.509" refers to Series X, section 509. The name identifies the section that standardizes the digital certificate format for public and private key management. In general, when someone writes about certificates, certs, X.509, or x509, it's all the same thing.
X.509 technology has been around since at least November 1988. That's when the first edition of the specification was released. It's not a perfect technology (they're on the ninth major revision right now), but it's good enough for many day-to-day uses.
I'm not going to claim that X.509 is simple. Public and private key cryptography is very technical and the X.509 file format is overly complicated. Years ago, I wrote my own X.509 parser, for both binary (DER) and encoded text (PEM) formats, and with support for individual certs and chains of certs. You really can't comprehend the full depth of complexity until you try to implement it your own parser. This is why almost everyone relies on someone else's existing library. The most popular library is
OpenSSL
.
At an overly-simplified view, each X.509 certificate contains (at minimum) a public key, and/or a private key, and/or a chain of parent keys. (A parent cert can be used to issue a child cert, creating a chain of certificates.) Data encrypted with the public key can only be decoded with the private key, and vice versa. Usually the private key is not distributed (kept private) while the public key is shared (made public).
X.509 Metadata
Buried inside the X.509 format are parameters that identify how the certificate can be used. Some certs are only for web sites (HTTPS), while others may only be for digitally signing documents.
Most certs also include information about the issuer and the issuee (the 'subject'). These are usually encoded text notations, such as:
-
CN: Common Name
-
OU: Organizational Unit
-
O: Organization
-
L: Locality (City or Region)
-
ST: State or Province Name
-
C: Country Name
So you might see a cert containing:
Subject: /CN=cai-prod/O=Adobe Inc./L=San Jose/ST=California/C=US/emailAddress=cai-ops@adobe.com
Issuer: /C=US/O=Adobe Systems Incorporated/OU=Adobe Trust Services/CN=Adobe Product Services G3
Depending on the X.509 parser, you might see these fields separated by spaces or converted to text (e.g., Country: US, Organization: Adobe Inc., etc.)
The reason I'm diving into X.509 is that C2PA uses these certs to digitally sign the information. As I previously demonstrated with
my forgeries
, you can't assume that the Subject or Issuer information represents the actual certificate holder. We trust that every issuing certificate provider, starting with the top-level CA provider, is trusted and reputable, filling in the information using validated and authenticated credentials. However, that's not always the case.
-
2011:
Fraudulent certs
were issued by real CA provider for Google, Microsoft, Yahoo, and Skype
-
2012: The trusted and reputable CA provider "TURKTRUST" issued
unauthorized certs
for Google, Microsoft, and others. (Even though the problem was identified, it was
nearly a year later
before TURKTRUST was revoked as an untrusted and disreputable CA provider.)
-
2013: Google and Microsoft
again
discovered
that fraudulent certs were issued by a real CA provider for some of their domains.
-
2015: A trusted and reputable
CA provider in China
was caught issuing unauthorized certificates for Google. As crypto-expert
Bruce Schneier wrote
, "Yet another example of why the CA model is so broken."
This is far from every instance. It doesn't happen often, but news reports every 1-2 years is enough to recognize that threat is very realistic. Moreover, if the company (like Leica) isn't as big as Google or Microsoft, then they might not notice the forged certificate.
X.509 Dates
Inside each cert should also be a few dates that identify when the certificate is valid:
-
Not Before
: A cert may be created at any time, but is not valid until after a specific date. Often (but not always), this is the date when the certificate was generated.
-
Not After
: Certs typically have an expiration date. After that date, the cert is no longer valid. With LetsEncrypt, certificates are only good for 3 months at a time. (LetsEncrypt provides a helper script that automatically renews the cert so administrators don't forget.) Other certificate authorities (CA servers) may issue multi-year certificates. The trusted CA providers (top of the cert chain) often have certs that are issued for a decade or longer.
With C2PA, every cert that I've seen (both real and forged) include these dates. Similarly, unless it is a self-signed certificate, every web server has these dates. In your desktop browser, you can visit any web site and click on the little lock in the address bar to view the site's certificate information. It will list the issuer, subject, and valid date ranges.
Expired Certs and Signing
On rare occasions, you might encounter web sites where the certificate has expired. The web browser detects the bad server certificate and displays an error message:
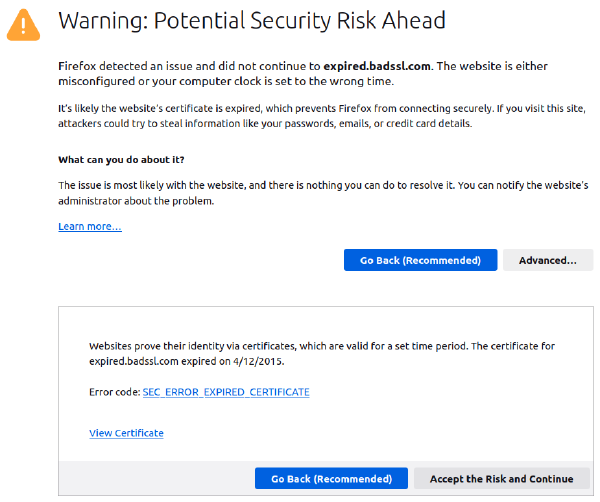
For a web site:
-
If you don't know what's going on, then the error message stops you from visiting a site that uses an invalid/expired certificate.
-
The temporary workaround is to ignore the expired date, use the certificate anyway, and visit the web site. (NEVER do this if the web site requires any kind of login.)
-
The long-term solution requires the web administrator to update the certs for the site.
But what about digital signatures, such as those issued with DocuSign or C2PA? In these cases, the public certificate is included with the signature. Since the public cert is widely distributed, they can't just reach out across the internet and update all of them.
An invalid certificate
must never be used
to create a new signature, but it
can be used
to validate an existing signature. As noted by
GlobalTrust
(a trusted certificate authority), there are a few situations to consider when evaluating the time range of a cert used for a digital signature:
Case #1: Post-date
: This occurs when the current time is before the Not Before date. (You almost never encounter this.) In this case, we can prove that an invalid certificate was used to sign the data. The signature must be interpreted as invalid, even if the certificate can be used to confirm the signature. (An invalid certificate cannot be used to create a valid signature.)
Case #2: Active
: If the current date falls between the Not Before and Not After dates, then the certificate's time range is valid. If the signature checks out, then the signature is valid.
Case #3: Expired
: This is where things get a little complicated. As noted by GlobalTrust, "Expired certificates can no longer produce valid signatures -- however, signatures set before expiry remain valid later. Software that issues an error here does not work in accordance with the standard."
This means two things:
-
You are not supposed to use an expired certificate to sign something after it has expired. An expired certificate is invalid for signing, and any new signatures must be treated as invalid.
-
If you have an expired certificate that can validate a signature, then the signature is valid.
If (like most of the world) you use OpenSSL to generate a digital signature, then OpenSSL checks the dates. The library refuses to sign anything using an expired certificate. And since Adobe's
c2patool
uses OpenSSL, it also can't sign the C2PA metadata using an expired certificate.
Except... There's a nifty Linux command-line tool called "faketime". (
sudo apt install faketime
) This program hijacks any system calls to the time() or clock() functions and returns a fake time to the calling application. To backdate the clock by 2 years for a single application, you might use:
faketime -f -2y date # display the date, but it's backdated 2 years
faketime -f -2y openssl ... # force openssl to sign something as if it were 2 years ago
faketime -f -2y c2patool ... # force c2patool to sign using an expired certificate
This way, you
can
generate a signature that appears valid using an expired certificate. After the expiration date, the backdated signature will appear valid because it can be verified by an expired certificate. (Doh!)
(Using faketime is much easier than taking your computer offline, rolling back the system clock, and then signing the data.)
This means that a malicious user with an expired certificate can always backdate a signature. So really, we need to change Case
#3 to make it more specific:
Case #3: Expired and Previously Verified
: If the cert is currently expired
and
you, or someone you trust, previously verified the signature when it wasn't expired, then the signature is still valid.
Case #4: Expired and Not Previously Verified (by someone you trust)
: What if you just received the document and the validating certificate is already expired? In this case, you can't tell if someone backdated the signature using something like 'faketime'.
Even if you trust the signing authority, or even if other certificate issuers in the chain are still valid, that doesn't mean that someone didn't backdate the expired certificate for signing. In this case, you cannot trust the signature and it must be treated as
invalid
.
Hello, Adobe
The reason I'm bringing up all of this: Adobe's certificate that they used for signing C2PA metadata expired on 2024-02-01 23:59:59 GMT. At FotoForensics, I have over a hundred examples of files with C2PA metadata that are now expired. I also have copies of a few dozen pictures from Microsoft that are about to expire (Not After 2024-03-31 18:15:27 GMT) and a few examples from other vendors that expire later this year.
-
In theory, the signer can always authenticate their own signature. Even after it expires, Adobe can authenticate Adobe, Microsoft can authenticate Microsoft, etc. This is because Adobe can claim that only Adobe had access to the cert and nobody at Adobe backdated the signature. (Same for Microsoft and other companies.)
-
If the signer is trusted, such as DocuSign (used for signing legal documents), then we can trust that it was previously validated. (This is Case #3 and we can trust the signature.)
But what about the rest of us? I'm not Adobe, Microsoft, Leica, etc. Maybe I don't trust all of the employees at these companies. (I shouldn't be require to trust them.) Consider this picture (click to view it at
FotoForensics
or Adobe's
Content Credentials
):

-
If you only trust the C2PA signature, then you have an expired certificate that validates the signature. Adobe's Content Credentials doesn't mention that the certificate is expired.
-
If you look at the timestamps, it claims that it was signed by Adobe on 16-Jan-2024; 16 days before the certificate expired. This means you had about two weeks to validate it before it expired. That's not very long.
-
If you look at the metadata, you can see that it was heavily altered. Taking the metadata at face value identifies a Nikon D810 camera, Adobe Lightroom 7.1.2 for Windows, and Photoshop 25.3 for Windows. The edits happened over a two-year time span. (That's two year between creation and the digital signing with C2PA's authenticity and provenance information.) You can also identify a lot of different alterations, including adjustments to the texture, shadows, lighting, spot healing, etc. (And all of that is just from the metadata!)
This picture is far from a "camera original".
I know a few companies that have said that they want to just relying on the C2PA validation step to determine if a picture is altered. If the C2PA signature is valid, then they assume the picture is valid. But in this case, the non-C2PA metadata clearly identifies alterations. Moreover, the C2PA signature is only able to be validated using an expired certificate. We trust that it was not backdated, but given all of the other edits, is that trust misplaced?
Keep in mind, this specific example is using Adobe. However, many other companies are considering adopting the C2PA specification. Even if you trust Adobe, do you really trust every other company, organization, and creator out there?
New Certs
According to the sightings at FotoForensics, Adobe updated their certificate days before it expired. The new certificate says Not Before 2024-01-11 00:00:00 GMT and Not After 2025-01-10 23:59:59 GMT. That means it's good for one year.
However, even though Adobe's new cert has a Not Before date of 2024-01-11, it wasn't rolled out until 2024-01-23. It took 12 days before FotoForensics had its first sighting of Adobe's new cert. Most companies generate their new cert and immediately deploy it. I'm not sure why Adobe sat on it for 12 days.
In the example picture above, the metadata says it was last modified and cryptographically signed on 2024-01-17, which is 6 days
after
the new cert was created. If I didn't suspect that Adobe did a slow release of their new certificate, then I'd probably be wondering why it was signed using the old cert after the new cert was available.
The problem of expiring certs will also be problematic when cameras, such as
Leica
,
Canon
, and
Nikon
, begin incorporating C2PA technology. Here are some of the issues:
-
Standalone cameras often have clocks that are unset or off by minutes or hours. (Do you want to capture that spontaneous photo, or set the clock first?) Unlike cellphone cameras, many DSLR cameras don't set the time automatically and lose time when the batteries are removed or replaced. If the clock isn't right, then the cert may not be valid for signing.
-
If the cert is expired, then the camera owner can always backdate the time on the device. This permits claiming that a new photo is old and backing up the claim with a C2PA signature. Even if you trust Canon's cert, you cannot extend that trust to the camera's owner.
-
The few standalone camera certs I've seen so far have only been valid for a year. That means you will need to update the firmware on your camera at least annually in order to get the new certs. I don't know any photographers who regularly check for firmware updates. New firmware also increases the risk of an update failing and
bricking
the camera or changing functionality that you previously enjoyed. (When doing a firmware update, vendors rarely change "just one thing".)
-
Many DSLR cameras lose vendor support after 1-2 years. (
Canon
is one of the few brands that offers 5 years for most cameras and 10 years on a few others.) Your new, really expensive camera may not receive new certs after a while. Then what do you do? (The answer? Stop using that camera for taking signed photos!)
Expired and Revoked
There's one other irony about C2PA's use of certificates. In their specification (
Section 1.4: Trust
), they explicitly wrote:
C2PA Manifests can be validated indefinitely regardless of whether the cryptographic credentials used to sign its contents are later expired or revoked.
This means that the C2PA decision makers probably never considered the case of an expired certificate being backdated. Making matters worse, C2PA explicitly says that
revoked certificates are acceptable
. This contradicts the widely accepted usage of certificates. As
noted by IBM
:
When x.509 certificates are issued, they are assigned a validity period that defines a start and end (expiration) date and time for the certificate. Certificates are considered valid if used during the validity period. If the certificate is deemed to be no longer trustable prior to its expiration date, it can be revoked by the issuing Certificate Authority (CA). The process of revoking the certificate is known as certificate revocation. There are a number of reasons why certificates are revoked. Some common reasons for revocation are:
-
Encryption keys of the certificate have been compromised.
-
Errors within an issued certificate.
-
Change in usage of the certificate.
-
Certificate owner is no longer deemed trusted.
In other words, if a C2PA signature is signed using an explicitly untrusted certificate, then (Section 1.4) the signature should still be considered "valid". This is a direct conflict with the X.509 standard.
C2PA's
Section 16.4: Validate the Credential Revocation Information
, includes a slight contradiction and correction, but doesn't improve the situation:
When a signer’s credential is revoked, this does not invalidate manifests that were signed before the time of revocation.
It might take a while for a compromised certificate to become revoked. According to C2PA, all signatures made by a known-bad-but-not-yet-revoked certificate are valid. (Ouch! And my coworker just remarked: "It's not like an election can occur in the intervening time. Oh wait, did I say the bad part out loud?")
If you are generating a forgery and have a revoked certificate, you can always backdate the signature to a time before the revocation date. According to C2PA, the signature must be accepted as valid.
With X.509 certs and web sites, revocation is very rare. However, this needs to change if these certs are embedded into devices for authoritative signatures. Some of the new cameras are embedding C2PA certificates for signing. If your camera is lost, stolen, or resold, then you need to make sure the certificate is revoked.
Legal Implications
[Disclaimer: I am not an attorney and this is not legal advice.]
The C2PA specification lists many
use cases
. Their examples include gathering data for open source intelligence (OSINT) and "providing evidence". Intelligence gathering and evidence usage typically come down to legal purposes. (Ironically, during a video chat discussion that I had with C2PA and CAI leadership last December, they mentioned that they had not consulted with any experts about how C2PA would be used for legal cases.)
I've occasionally been involved in legal cases as a subject matter expert or unnamed technical consultant. From what I've seen, legal cases often drag on for years. Whether it's an ugly divorce, child custody battle, or burglary charge, they are never resolved in months. (All of those TV crime shows and legal dramas, where they go from crime to arrest to trial in days? Yeah, that kind of expedited timeline is fiction.) I sometimes see cases where evidence was collected but went untouched for years. I've also seen a lot of mishandled evidence. What most people don't realize, is that usually a named party in the lawsuit produces the evidence; it's not collected through law enforcement or a trusted investigator. Also, it's usually not handled properly so there are plenty of opportunities for evidence tampering. (As a subject matter expert, I enjoy catching people who have tampered with evidence.)
So, consider a hypothetical case that is based on photographic evidence with C2PA signatures:
-
The files were collected, but the signatures were never checked.
-
Due to issues with evidence handling, we can't even be certain when they were digitally signed, how they were handled, or how they were collected. There is plenty of opportunity for evidence tampering.
-
By the time someone does check the files, the certificates have expired. They may have expired prior to being documented as evidence.
This is the "Case
#4" situation: expired and not validated by a trusted party. Now it's up to the attorneys to decide what to do with an expired digital signature. If it supports their case, they may ignore the expiration date and use it anyway. If it doesn't support their client's position, then they might get the evidence thrown out or flagged as tampered,
spoiled
, altered, or fabricated. C2PA's bad decision to use X.509 certificates with short expiration windows helps with any "
motion to suppress
", "
suppression of evidence
", or "
exclusion of evidence
."
Without C2PA, we have to rely on good old forensics for tamper detection. With these methods, it doesn't matter when the evidence was collected or who collected it as long as there is no indication of tampering. C2PA adds in a new way to reject otherwise legitimate evidence.
The same concerns apply to photojournalism. If a picture turns up with an expired certificate, does that mean it is just an old photo? Or could it be fabricated and backdated so that it appears to have a valid signature from an expired certificate?
There are many ways to do cryptography and many different frameworks for managing public and private keys. The use of X.509 certificates with short expiration dates, and the acceptance of revoked certificates, just appears to be more bad decisions by C2PA. The real problem here isn't the use of X.509 -- that's just a case of using the wrong tool for the job. Instead, the bigger problem is leaving the signing mechanism in the hands of the user. If the user has malicious intent, then they can use C2PA to sign any metadata (real or forged) as if it were real and they can easily backdate (or post-date) any signature.
Značky: #FotoForensics, #Authentication, #Programming, #Network, #Politics, #Forensics