Récemment j'ai du intervenir sur ma tour parce que j'avais plus tellement de place. J'ai du vite acheter un autre disque dur pour y remédier. Ce qui me donne l'occasion de parler de cette belle technologie sur laquelle je m'étais promis de faire un petit tuto un de ces jours.
En théorie
RAID est l'a...
Récemment j'ai du intervenir sur ma tour parce que j'avais plus tellement de place. J'ai du vite acheter un autre disque dur pour y remédier. Ce qui me donne l'occasion de parler de cette belle technologie sur laquelle je m'étais promis de faire un petit tuto un de ces jours.
En théorie
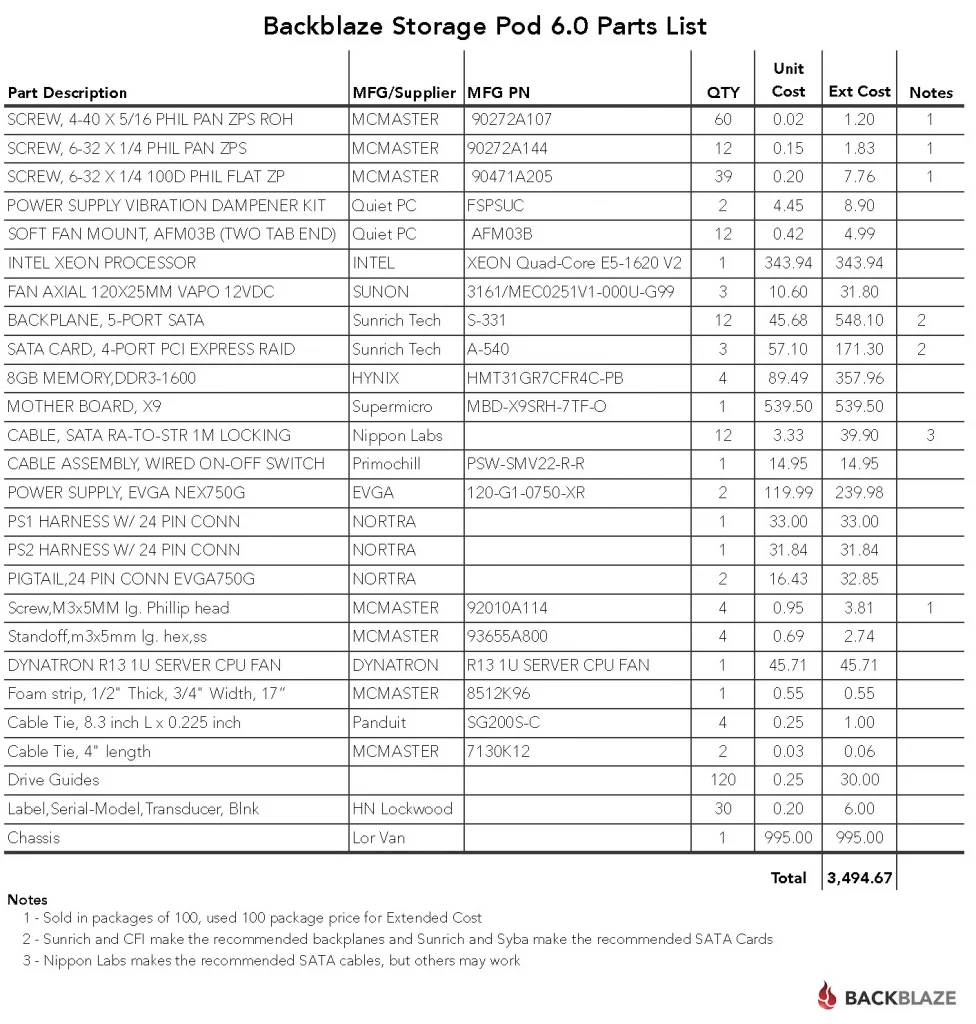
RAID est l'acronyme de Redundant Array of Independent Disks (Alignement redondant de disques indépendants), et comme son nom l'indique, il va permettre de regrouper plusieurs disques durs et d'y instaurer une politique de stockage pour faire de la redondance, de l’agrégation de taille, enfin ça répond à plein de besoins différents. En fait on ne devrait pas vraiment parler d'un seul RAID, mais bel et bien de la famille des RAIDs, car en effet il y a autant de RAIDs que de besoins différent.
On va présenter les assemblages RAID les plus utilisés. Pour plus de détails, je vous conseille la page Wikipédia qui est très claire et qui contient des schémas très explicites.
Dans la suite, on va beaucoup parler de bandes de stockage : il s'agit d'une quantité de stockage de valeur prédéfinie, qui correspond à une "section" contiguë du disque qui la contient. Dans ce modèle, lors de l'écriture sur le volume, une bande est d’abord remplie avant d'en entamer une suivante. Il s'agit en fait d'abstraire le stockage et de pouvoir mieux comprendre la répartition des données sur les différents disques.
RAID 0
Les bandes sont tout bonnement distribuées sur les disques, toujours dans le même ordre. On remplit donc une bande par disque, puis une fois qu'on a touché à tous les disques, on repart du premier disque et on recommence une couche de bandes. Tous les disques contiennent des données différentes. Ainsi, si vous avez n disques durs de capacité exploitable x, la capacité totale du montage sera nx.
- Avantages : Ce montage permet d'utiliser le plus grand espace possible de votre assemblage. De plus, en moyenne, les accès disques parallèles seront plus rapide, pour peu que ces accès disques se fassent dans des bandes différentes et sur des disques différents.
- Inconvénients : Il suffit de perdre un seul disque pour corrompre l'intégralité des données. Or, statistiquement, plus on a de disques, plus on a de chances d'en perdre.
RAID 1
Les bandes sont écrites à l’identique sur tous les disques. Tous les disques contiennent exactement les même données. Ainsi, si vous avez n disques durs de capacité exploitable x, la capacité totale du montage sera x.
- Avantages : C'est le montage qui permet la plus grande sécurité des données faces aux pannes : tant qu'il vous reste un disque fonctionnel, vos données sont intactes et complètes. Les accès disques sont aussi nettement améliorés, avec une vitesse théorique multipliée par le nombre de disques dans le montage.
- Inconvénients : Il est frustrant d'avoir beaucoup de disques durs pour avoir au final l'espace d'un seul disque. Évidemment les données sont très sûres mais quand même, faut pas pousser...
RAID 5
Les bandes sont réparties sur tous les disques sauf un, qui reçoit une bande de parité. La bande de parité est tout simplement une bande dont chaque bit est obtenu en appliquant le OU exclusif (XOR) à l'ensemble des bits correspondants dans les bandes alignées des autres disques. Cette bande de parité est attribuée à chaque disque alternativement au fil des couches de bandes remplies. Donc si un disque vient à tomber en panne, pour chaque couche de bande, si la bande du disque en panne est la bande de parité, alors les données de la couche sont intactes. Si la bande contient de la donnée, alors elle peut être recalculée à partir des autres couches de données et celle de parité. C'est du calcul logique, et c'est la force du XOR. Ainsi, si vous avez n disques durs de capacité exploitable x, la capacité totale du montage sera (n-1)x.
- Avantages : Un bon compromis entre place exploitable et sécurité des données. On se donne le droit de perdre un disque dur dans la bataille. Pour retrouver l'usage des données, il suffit de remplacer le disque défaillant et les données sont reconstruites.
- Inconvénients : Ça dépends des cas, mais un droit à un unique disque dur en panne, ça peu être peu. Pour certain ça peut être insuffisant.
RAID 6
Il s'agit d'une extension du RAID 5 dans laquelle on se permet de pouvoir perdre plus d'un disque. La solution étant d'attribuer plus de bandes de "parité" par couche, une par nombre de pannes maximum permises. Ici, j'utilise les guillemets car il ne s'agit plus vraiment de la parité simple de la logique de base, mais d'un truc chelou reposant sur un principe tout autre dont je ne pas trop vous parler parce que j'en ignore tout. Donc si vous avez n disques durs de capacité exploitable x, et si vous mettez en place k bandes de redondance par couche, la capacité totale du montage sera (n-k)x.
- Avantages : On se sent un peu plus à l’abri des intempéries matérielles, au pris d'un peu de place de stockage.
- Inconvénients : Le principe chelou dont je vous ai parlé, enfin dont je ne vous ai pas parlé pour être honnête, eh bien il est tellement chelou qu'il pète pas mal les performances. Et pour couronner le tout, la plupart des implémentations de ce type d'assemblage est bien moins stable que les autres.
Il est également possible de combiner les RAIDs. Une combinaison fréquente est le RAID 10 (RAID 1 + RAID 0). Par exemple si on a 10 disques, on peu monter 2 RAID 1 de 5 disques chacun, puis assembler ces deux volumes en RAID 0. On a également aussi le RAID 50, combinaison dur RAID 5 et du RAID 0 selon le même principe.
La gestion du RAID
Je vous parlais de différentes implémentations du RAID. En fait, le RAID n'est pas un programme en tant que soi, juste un ensemble de spécifications. Du coup chacun y va de sa sauce : il existe des implémentations libres et propriétaires, logicielles et matérielles. Les solutions matérielles se basent sur du matériel dédié (un contrôleur RAID), le système d'exploitation n'a donc pas à s'occuper de ça et le plus souvent ces solutions marchent out of the box, sans avoir besoin de configurer quoi que ce soit. Mais elles ont l'immense inconvénient d'être propriétaire dans leur quasi-totalité, et pour le coup il n'existe aucun standard. Dans certains cas, si votre contrôleur RAID rend l'âme, il vous faudra acquérir exactement le même modèle de contrôleur, sinon, peu importe que vos disques soient tous intacts, plus rien ne pourra les lire, et vous serez alors en légitime position d'être fort contrarié. À mon humble avis, le principal argument des RAIDs matériel auparavant était les meilleures performances. Aujourd'hui cet avantage est de plus en plus obsolète, car désormais les machines sont bien plus puissantes qu'il y a 15 ans et les programmes de RAID ont été nettement optimisés et stabilisés. Cette différence de performance est aujourd'hui presque intangible.
En pratique
J'ai hérité par un ami d'une tour de bureau. Elle est bien cool car elle contient une grande baie de disques et pas mal de ports SATA (bien entendu, vous pouvez faire votre RAID avec des disques branchés en USB si vous le souhaitez). J'ai donc décidé d'en faire un NAS fait main.
Choix des armes
J'ai donc initialement acheté 3 disques de 3 To chacun (des Western Digital Red, gamme dédiée justement aux usage en RAID) et j'ai opté pour un RAID 5 logiciel. Et sur Linux, le programme de RAID par excellence est mdadm. J'ai décidé de garder branché le disque dur d'origine (500 Go) mais de ne pas l'intégrer au RAID, il sert uniquement de disque de démarrage. Notez que si j'avais voulu optimiser les performances, j'aurais pu troquer ce disque pour un petit SSD, mais bon, je suis déjà content comme ça.
Par ailleurs, pour faire de la place dans la baie de disques, j'ai du déménager le disque de démarrage dans la baie frontale, celle destinée à accueillir les périphériques comme le lecteur optique.

Le 4ème disque du RAID, on en parlera plus tard. Je l'ai acheté bien après.
Pour ça j'ai utilisé un adaptateur 3,5 pouces vers 5,25 pouces bien pratique, qui m'a permis de fixer bien solidement le disque dur au lieu de le laisser se balader dans la tour.
Partitionnement et formatage
Du côté software, je me retrouve avec un disque sda de démarrage, et sdb, sdc et sdd des disques vierges prêts à être assemblés en RAID. Avant ça, j'ai besoin de les partitionner. J'utilise donc fdisk pour les trois disques à tour de rôle, je choisis une table de partitions GPT et j'y crée une unique partition de type "Linux RAID" (code 29 dans fdisk).
Création de l'assemblage RAID
C'est tout bête, ça tient en une seule ligne de commande :
mdadm --create --verbose /dev/md0 --level=5 --raid-devices=3 /dev/sdb1 /dev/sdc1 /dev/sdd1
Dans cette commande, j'indique que le nom du volume abstrait sera /dev/md0, que ce sera un RAID 5, qu'il comporte 3 disques et je lui précise les partitions que je veux utiliser.
Pour suivre l'évolution de la création de l'assemblage, jetez un coup d'oeil au fichier /proc/mdstat. Ce fichier sera votre nouvel ami, c'est lui qu'il faudra consulter dès que vous ferez une opération qui touche au RAID.
Puis j'ajoute l'assemblage à la configuration de mdadm pour que celui-ci me l'assemble au démarrage :
mdadm --detail --scan >> /etc/mdadm.conf
Puis il ne vous reste plus qu'à mettre votre système de fichier préféré sur le volume créé !
mkfs.ext4 /dev/md0
Pour que votre assemblage soit monté au démarrage, j'ajoute à mon /etc/fstab :
/dev/md0 /mnt/data ext4 defaults 0 0
Il ne faut pas confondre assemblage et montage, il s'agit de deux étapes lors de la connexion d'un RAID. On doit assembler un RAID afin qu'il soit reconnu comme un volume propre, puis on doit monter notre volume pour pouvoir lire et écrire dessus.
Enfin on monte le volume :
mkdir /mnt/data
mount /mnt/data
Ayé vous avez un RAID 5 qui fonctionne !
Il est recommandé de procéder régulièrement à des reconstruction de RAID, opération qui va vérifier la cohérence de l'assemblage. Il s'agit d'une opération transparente mais qui dure plusieurs heures et qui va se traduire par une forte augmentation de l'activité des disques. Pour ça il vous faudra lancer un petit programme sans arguments, raid-check, à un intervalle raisonnable, disons, toutes les semaines. Choisissez un horaire de faible activité, comme la nuit du samedi au dimanche à 3h du matin. Pour ça, faites vous plaisir, entre la crontab et les timers de systemd, on manque pas de solutions.
Ajout d'un nouveau disque à l'assemblage
Mon RAID 5 était constitué de 3 disques de 3 To ce qui nous fait 6 To exploitables, si vous avez bien suivi. 6 To, c'est un grand espace, il m'a suffi pendant presque 2 ans... Puis j'ai eu besoin de plus de place. J'ai donc racheté un autre disque (même modèle, même taille) que j'ai fourré dans ma tour. Je vous avoue que sur le coup, j'étais encore puceau au niveau extension de RAID, j'ai donc flippé énormément et j'ai fait une sauvegarde de mes 6 To sur divers disques externes que j'ai pu trouver dans ma caverne. Je vous raconte pas comme c'était pénible...
Petites observations à ce niveau :
- Remarquez que l'ordre des disques dans le nommage des périphériques physiques (sdX) et tout sauf fixe. En théorie, il faut être préparé à ce que vos disques changent de noms. Votre petit
sdb chéri que vous avez bordé et vu s'endormir dans le creux douillet de son lit un soir peut très bien vous trahir et s'appeler sdc au petit matin dès le prochain redémarrage. Bon c'est un peu exagéré, mais une chose est sure, il ne faut jamais faire confiance au nommage des périphériques physiques (c'est pour ça entre autres qu'il faut privilégier la désignation par UUID dans la fstab). - mdadm se fiche complètement du nommage de ses périphériques. Il utilise sa propre magie noire pour déterminer les membres d'un assemblages. En conclusion, ne vous tracassez pas pour retrouver le nom de vos disques de votre assemblage, mdadm, lui, s'y retrouvera toujours.
Cependant, faites quand même gaffe lorsque vous allez ajoutez votre nouveau disque dur. Par exemple chez moi, le nouveau disque s'est vu nommé sdb, tandis que les autres s'étaient vu relégués en sdc, sdd et sde. Faut juste le savoir et traiter les disques pour ce qu'ils sont, et non pas des étiquettes à trois lettres.
Tout ce que j'ai eu à faire, en définitive, a été de partitionner-formater mon nouveau disque ainsi que l'ont été ses aînés, puis j'ai lancé les deux commandes suivantes :
mdadm --add /dev/md0 /dev/sdb1
mdadm --grow --raid-devices=4 --backup-file=/root/grow\_md0.bak /dev/md0
La première va juste indiquer à mdadm qu'on lui ajoute un disque, mais sans plus. C'est la deuxième commande qui va lancer l'opération de reconstruction (rééquilibrage de l'assemblage). Opération qui dure plusieurs heures, donc suivez son déroulement dans /proc/mdstat.
Une fois que c'est terminé, il faut maintenant procéder à l'extension du système de fichier lui même. Et là vous priez pour avoir choisi un système de fichier pas trop stupide qui accepte ce genre d'opération. Rassurez-vous, ext4 le supporte très bien.
Il le supporte même tellement bien que vous pouvez le faire directement à chaud, sans démonter votre volume. Pour ça, premièrement, si vous utilisez une connexion SSH, ouvrez une session tmux. Il serait bête qu'un incident réseau de rien du tout vienne corrombre tout votre système de fichire tout de même. Puis il vous faudra exécuter :
resize2fs -p /dev/md0
Il va vous mettre en garde et ronchonner un tantinet que votre disque est toujours monté, mais écoutez, il s'en remettra, dans la vie on fait pas toujours ce qu'on veut. Les minutes passent, vous vous rongez les ongles, vous prenez un café, vous videz un pot de glace, et normalement, si tout se passe bien, le système de fichier aura été étendu à tout l'espace disponible sur l'assemblage. Félicitations !
Conclusion
J'ai rencontré beaucoup de monde m'ayant dit qu'ils préféraient rester éloigner autant que possible de RAID parce que ça leur faisait peur. En réalité, il n'y a rien d'effrayant là dedans. mdadm est un outil ma foi fort bien codé et les années ont prouvé qu'il était fiable. Il ne faut pas avoir peur du RAID. Enfin un peu quand même, faut pas faire n'importe quoi.
 chevron_right
chevron_right