-
chevron_right
C2PA's Butterfly Effect
pubsub.slavino.sk / hackerfactor · Thursday, 16 November - 15:59 edit
- label
-
Throwing Shade
pubsub.slavino.sk / hackerfactor · Sunday, 22 October, 2023 - 02:26 edit · 7 minutes
-
The text above the picture has erasure marks. These appear as some black marks after the word "Eclipse" and below the word "day". Someone had poorly erased the old text and added new text.
-
The Sun is never that large in the sky.
- If the Sun is behind the pyramid, then why is the front side lit up? Even the clouds show the sunlight on the the wrong side.
-
The Moon's orbit around the Earth isn't circular; it's an ellipse. When a full moon happens at perigee (closest to the Earth), it looks larger and we call it a "super-moon". A full moon at apogee (furthest away) is a "mini-moon" because it looks smaller. Similarly, if an eclipse that happens when the Moon is really close to the Earth, then it blocks out almost all of the Sun. However, the Oct 14 eclipse happened when the Moon was further away. While the Moon blocked most of the Sun, it did not cover all of the Sun. Real photos of this eclipse show a thick ring of the Sun around the Moon, not a thin ring of the corona that is shown in this forgery.
-
I went to the
NASA web site
, which shows the full path of the total eclipse. The path of totality for this eclipse did go through a small portion of Yucatán, but it did not go through
Chichén Itzá
. At best, a photo from Chichén Itzá should look more like my photo: a crescent of the eclipse.
-
At Chichén Itzá, the partial eclipse happened at 11:25am - 11:30am (local time), so the Sun should be almost completely overhead. In the forgery, the Sun is at the wrong angle. (See Sky and Telescope's
interactive sky chart
. Set it for October 14, 2023 at 11:25am, and the coordinates should be 20' 40" N, 88' 34" W.)
-
Google Maps has a great street-level view of the Mayan pyramid. The four sides are not the same. In particular, the steps on the South side are really eroded, but the North side is mostly intact. Given that the steps in the picture are not eroded, I believe this photo is
facing South-East
(showing the North and West side of the pyramid), but it's the wrong direction for the eclipse. (The eclipse should be due South by direction and very high in the sky.)
-
Google Street View, as well as other recent photos, show a roped off area around the pyramid. (I assume it's to keep tourists from touching it.) The fencing is not present in this photo.
- The real pyramid at Chichén Itzá has a rectangular structure at the top. Three of the sides have one doorway each, while the North-facing side has three doorways (a big opening with two columns). In this forgery, we know it's not showing the South face because both stairways are intact. (As I mentioned, the South-facing stairwell is eroded.) However, the North face should have three doorways at the top. The visible sides in the photo have one doorway each, meaning that it can't be showing the North face. If it isn't showing the North side and isn't showing the South side, then it's not the correct building.
-
Here to Help
pubsub.slavino.sk / hackerfactor · Monday, 2 October, 2023 - 19:49 edit · 10 minutes
-
Windows hit a Patch Tuesday and wanted him to reboot. He didn't want to reboot, so he (very non-technical) tried to back out the patch. (Oh no...)
-
In doing so, he somehow also turned off Windows Defender.
- Then he wanted to open an attachment from one of his far-right emails. "This program is from an unknown source, do you trust it?" YES! "This wants to access the hard drive, let it?" YES! "This wants to access your contact list, let it?" YES! "This needs to access the network, let it?" YES! He didn't know what all of the prompts were, so he just kept clicking YES, YES, YES until it installed.
-
Too many updates? Users learn to not update right now, often delaying updates for weeks or longer. Worse: Some applications can block updates. (Poof! The problem of too many updates has stopped! Of course, this makes you infinitely less secure.) And at least one user decided to forcefully back out an essential update.
In my opinion, the correct solution would be for Windows to provide a central update scheduler rather than requiring every application to manage updates independently. Even if it checks daily, at least it isn't constantly checking. (Of course, standardizing this would require a significant development effort, as well as a specification like an IETF RFC or something from ISO .) -
Too many prompts? This trains users to always select "yes". Perhaps it would be better to have one prompt that lists all of the required permissions: "This application requires hard drive access, access to your contact list, and network access." This is what Android and iOS do. If developers don't declare permission up front, then they don't get the permissions. Some permission combinations could even trigger a warning, such as "These access privileges are commonly requested by computer viruses. Are you sure you want to install it?" Or maybe alternate yes/no responses to break the "yes, yes, yes" pattern. A really smart system could force a sandbox until after the program is used a few times in order to establish an access pattern.
In any case, prompt after prompt after prompt where "yes" means "enable it", is just a fast way to train users how to install malware. - Having built-in ads and "personalized recommendations" as a feature in the operating system may be a good way for Microsoft to generate revenue, but it leads to insecurity. Users can't distinguish spam/malware and an OS "feature". At best, users get annoyed and figure out how to turn it off. At worst, they end up installing malware because they can't tell the difference between an OS-provided ad and a virus ad.
-
 chevron_right
chevron_right
We now know who killed the “Lady of the Dunes”
news.movim.eu / ArsTechnica · Tuesday, 29 August, 2023 - 18:17 · 1 minute
-
Hot or Not
pubsub.slavino.sk / hackerfactor · Sunday, 27 August, 2023 - 19:56 edit · 6 minutes
-
The bandwidth usage as seen by the physical server (dom0). This includes all of the bandwidth used by each of the virtual machines (VMs). I have the option of drilling down by minute, hour, etc. and by specific VM. To monitor the network load and view the usage graphs, I use '
vnstati
'. (sudo apt install vnstati)
-
I can drill down into each VM and quickly see the uptime, system load, and disk space usage. If they ever display as yellow or red, then I know there's an issue. (These are just the unix commands 'upload' and 'df', along with hard-coded thresholds for alerts.)
-
My physical servers have internal sensors for the fans and temperatures. I used to use the 'sensors' command, but that only showed a fraction of the information. Now I'm using 'ipmi-sensors'. The catch here is that the number of sensors and fans varies by computer hardware. My R340 systems report different information compared to my older R320s. In the above picture, I intentionally have the fans running fast in order to keep the system cooler.
-
Getting the machine room and cabinet temperatures was a little more complicated. I purchased some
temperature sensors
from Amazon and hooked them up to a
serial-to-USB
dongle. One hangs down to the bottom of the cabinet, measuring the room temperature. The other is at the top of the cabinet, measuring the overall cabinet temperature. There's typically a 5°F (2.7°C) difference.
- I'm using Dell servers. That means I can use a Dell program called 'perccli64' to view the drive status. This gives me details like the drive's capacity, temperature, and error rates. I can also drill down and see the drive's make/model and other information. This allows me to detect a bad drive and replace it long before it fails.
-
Air Quality
: For the air quality, I download data directly from the US Environmental Protection Agency (EPA). Their
Air Quality System API
is free and easy to use. You call the correct URL and they give you a JSON with the data. I'm parsing the data for just the local (Fort Collins, Colorado) information. Since some of the reporting locations are within a few miles of my office, this is as good as running my own air quality sensors.
- Weather : I'm also tracking the local weather since heat and humidity can impact the server's running temperatures. For this, I'm harvesting free data directly from the National Weather Service's API . Again, I just parse their JSON for the fields that interest me.
-
Many COTS solutions require uploading data to "the cloud". If I lose internet access, then I'd lose access to this monitoring data. With my homemade solution, I may lose remote weather information, but I can still monitor my local sensors.
-
A single COTS solution may not monitor everything I want to monitor. For example, most COTS options monitor one outside and one inside temperature sensor. But I want to compare outside with inside the office, inside the machine room, and inside the server rack.
- COTS definitely has the technical advantage. Nothing to wire up and no circuit boards to solder. Given my limitations with hardware (being a programmer is not the same as being an electrical engineer; when am I supposed to use a resister?), off-the-shelf will certainly be easier to deploy. But as a programmer, homemade means I have much more control over how I use the data.
-
Sc
chevron_right
Typing Incriminating Evidence in the Memo Field
news.movim.eu / Schneier · Tuesday, 27 June, 2023 - 20:36
-
Unconventional Wisdom
pubsub.slavino.sk / hackerfactor · Saturday, 17 June, 2023 - 23:44 edit · 10 minutes
- The attackers were querying my web server over IPv4. I configured an HTTPS server for them to access.
- HTTPS uses a TLS certificate for security. The TLS certificate includes the domain name for the honeypot.
- The DNS entry for the honeypot lists an IPv6 address.
-
Regardless of whether it is IPv4 or IPv6, blocking all of ICMP is a bad idea. Echo request (ping) is a specific type of ICMP packet. It is always safe to block incoming Echo Request packets.
-
IPv6 uses ICMPv6 for neighbor discovery and related routing detection. If you block all of ICMPv6, then you'll break your IPv6 rounting. However, neighbor discovery does not rely on ping packets. You can safely block IPv6 ping.
- There are some transitional protocols for operating systems that are migrating from IPv4 to IPv6. These include 4in6, 6in4, 4over6, 6over6, and Teredo . Teredo was Microsoft's transitional protocol for connecting IPv4 systems to the IPv6 network. Teredo does use ICMPv6 ping, so blocking ping will prevent Teredo users from connecting to your IPv6 server. However, Microsoft turned off all of their Teredo relays in 2018 . Today, nobody uses Teredo. (The only Teredo packets I've received have been hostile bots trying to anonymize themselves by relaying through the few remaining Teredo servers.)
-
Indictment Documents
pubsub.slavino.sk / hackerfactor · Sunday, 11 June, 2023 - 19:40 edit · 9 minutes
-
Initially, someone wrote a source document. However, that specific version was never released. Instead, that document was printed out multiple times. One copy was filed with the DOJ and another copy went to the US Federal Court in Florida. The various attorneys, members of congress, and other interested parties probably also got their own authoritative copies.
-
The DOJ received their copy, put their stamp on it, and went though their standard ingest process for recording the filing and public release. This became the document version found at justice.gov.
- The US Federal Court in Florida received their copy, put their stamp on it, and went though their standard ingest process for recording the filing and public release. This became the document version found at flsd.uscourts.gov.
-
NCMEC and ESP 2022 Reporting Summary
pubsub.slavino.sk / hackerfactor · Tuesday, 9 May, 2023 - 22:56 edit · 15 minutes
- Uncooperative
- Abusively Cooperative
- Basic Cooperative
- Aggressively Cooperative
-
Consider loosening
18 USC 2252
, so that an ESP can search their own holdings for potential CP (or CSAM). This same law also prohibits an ESP from using NCMEC's hash-sharing service for specifically searching for CP.
-
Modify
18 USC 2251
, which only focuses on visual content and not textual, audio, or other types of media. As it is written, a text-only chatroom never needs to report to the CyberTipline since it's not visual.
-
Stop using weak hashes! MD5 has not been recommended for use for decades. (Please please please stop promoting it!)
PhotoDNA is reversible
to an image and effectively the same as distributing a copy of the picture. Facebook's
TMK+PDQF
is so laughably inaccurate that nobody should use it for anything. Also, remove the clause in NCMEC's hash sharing program's license terms that prevent ESPs from evaluating the effectiveness of the hashes that NCMEC provides.
-
NCMEC should not change the meaning of ESP's submitted information since it can impact everything from the chain of custody to illegal searches. For example, the CyberTipline report has a boolean field called "File Viewed By Company". In the report that law enforcement receives, the wording is changed by NCMEC to "Did Reporting ESP view entire contents of uploaded file?" This may sound like a minor word change ('view the file' vs 'view the entire file'), but it has huge implications with respect to illegal search and seizure. (I'm not a legal expert, but I think it's related to
United States v. Jacobsen
. See: "
Searching and Seizing Computers and Obtaining Electronic Evidence in Criminal Investigations
", page 10, 'Private Searches'.)
Basically, law enforcement cannot look at anything beyond what the ESP looked at without getting a warrant first. If the ESP looks at a thumbnail of an image, the first few seconds of a video, or some other part of the file (all enabling the "File Viewed By Company" checkbox), then NCMEC should not claim that the ESP viewed the "entire contents". Unless the ESP viewed the full-sized imagery, entire video, all metadata, and every byte in the file, they cannot legitimately claim to have viewed the "entire contents" of the uploaded file.
As part of FotoForensics, I try to track major occasions, such as holidays, weather warnings, and astronomical events. Often, I'll see fake photos of the occasion before it happens. I might see photos of a major blizzard burying a neighborhood days before the storm hits or a beautiful picture of a full moon a week before the full moon. What I'm usually seeing are forgers creating their pictures before the event happens.
Similarly, I often see fakes appear shortly after a major event.
Last Saturday (Oct 14), we had a great solar eclipse pass over North and South America. This was followed by some incredible photos -- some real, some not.
I tried to capture a photo of the eclipse by holding my special lens filter over my smartphone's camera. Unfortunately, my camera decoded to automatically switch into extended shutter mode. As a result, the Sun is completely washed out. However, the bokeh (small reflections made by the lens) clearly show the eclipse.

I showed my this photo to a friend, and he one-upped me. He had tried the same thing and had a perfect "ring of fire" captured by the camera. Of course, I immediately noticed something odd. I said, "That's not from Fort Collins." I knew this because we were not in the path of totality. He laughed and said he was in New Mexico for the eclipse.

The first time I saw this, I immediately knew it was fake. Among other things:
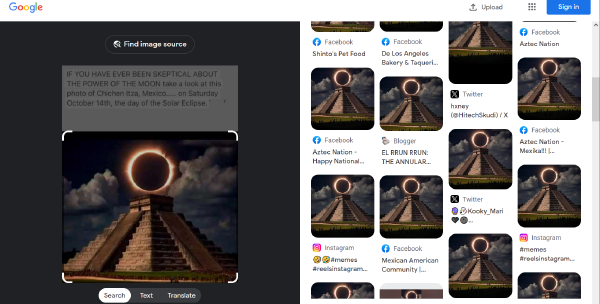
These include sightings from Instagam , LinkedIn , Facebook , TikTok , the service formally known as Twitter, and many more. Everyone shared the photo, and I could not find anybody who noticed that it was fake.
Ideally, we'd like to find the source image. This becomes the "smoking gun" piece of evidence that proves this eclipse photo is a fake. However without that, we can still use logic, reasoning, and other clues to conclusively determine that it is a forgery.
I can't rule out that the entire image may be computer generated or from some video game that I don't recognize. However, it could also be a photo from something like a museum diorama depicting what the pyramid may have looked like over a thousand years ago. (Those museum dioramas almost never have people standing on the miniature lawns.)
In any case, the eclipse was likely added after the pyramid photo was created.

Now keep in mind, I've already debunked the size of the Sun, the totality of the eclipse, and the angle above the horizon. This picture also has the same problem with the wrong side of the pyramid being in shadow. Moreover, it contradicts the previous forgery: it shows the eclipse happening on the other side of the pyramid, no people, and different cloud coverage at the same time on the same day.
With this second forgery, I was able to find the source image. The smoking gun comes from a desktop wallpaper background that has been available since at least 2009:

In this case, someone started with the old desktop wallpaper image, gave it a red tint, added clouds, and inserted a fake solar eclipse.
The same skills needed to track down forgeries like this are used for debunking fake news, identifying photo authenticity, and validating any kind of photographic claim. Critical thinking is essential when evaluating evidence. The outlandish claims around a photo should be grounded in reality and not eclipse the facts.
Similarly, I often see fakes appear shortly after a major event.
Last Saturday (Oct 14), we had a great solar eclipse pass over North and South America. This was followed by some incredible photos -- some real, some not.
I tried to capture a photo of the eclipse by holding my special lens filter over my smartphone's camera. Unfortunately, my camera decoded to automatically switch into extended shutter mode. As a result, the Sun is completely washed out. However, the bokeh (small reflections made by the lens) clearly show the eclipse.
I showed my this photo to a friend, and he one-upped me. He had tried the same thing and had a perfect "ring of fire" captured by the camera. Of course, I immediately noticed something odd. I said, "That's not from Fort Collins." I knew this because we were not in the path of totality. He laughed and said he was in New Mexico for the eclipse.
Ring of Truth
Following the eclipse, FotoForensics has received many copies of the same viral image depicting the eclipse over a Mayan pyramid. Here's one example:The first time I saw this, I immediately knew it was fake. Among other things:
These include sightings from Instagam , LinkedIn , Facebook , TikTok , the service formally known as Twitter, and many more. Everyone shared the photo, and I could not find anybody who noticed that it was fake.
Ideally, we'd like to find the source image. This becomes the "smoking gun" piece of evidence that proves this eclipse photo is a fake. However without that, we can still use logic, reasoning, and other clues to conclusively determine that it is a forgery.
Looking Closely
Image forensics isn't just about looking at pixels and metadata. It's also about fact checking. And in this case, the facts don't line up. (The only legitimate "facts" in this instance is that (1) there is a Mayan pyramid at Chichén Itzá in Yucatán, Mexico, and (2) there was an eclipse on Saturday, October 14.)I can't rule out that the entire image may be computer generated or from some video game that I don't recognize. However, it could also be a photo from something like a museum diorama depicting what the pyramid may have looked like over a thousand years ago. (Those museum dioramas almost never have people standing on the miniature lawns.)
In any case, the eclipse was likely added after the pyramid photo was created.
Moon Shot
While I couldn't find the basis for this specific eclipse photo, I did see what people claim is a second photo of this same eclipse at the same Mayan pyramid. I found this version of it at Facebook , but it's also being virally spread across many different social media platforms.Now keep in mind, I've already debunked the size of the Sun, the totality of the eclipse, and the angle above the horizon. This picture also has the same problem with the wrong side of the pyramid being in shadow. Moreover, it contradicts the previous forgery: it shows the eclipse happening on the other side of the pyramid, no people, and different cloud coverage at the same time on the same day.
With this second forgery, I was able to find the source image. The smoking gun comes from a desktop wallpaper background that has been available since at least 2009:
In this case, someone started with the old desktop wallpaper image, gave it a red tint, added clouds, and inserted a fake solar eclipse.
Total Eclipse of the Art
It's easy enough to say "it's fake" and to back it up with a single claim (e.g., wrong shadows). However, if this were a court case or a legal claim, you'd want to list as many issues as possible. A single claim could be contested, but a variety of provable inconsistencies undermines any authenticity allegedly depicted by the photo.The same skills needed to track down forgeries like this are used for debunking fake news, identifying photo authenticity, and validating any kind of photographic claim. Critical thinking is essential when evaluating evidence. The outlandish claims around a photo should be grounded in reality and not eclipse the facts.
Značky: #FotoForensics, #Network, #Forensics
I've been doing a lot of traveling recently. Besides my regular work, I also meet up with friends and inevitably am asked to help them with their computers. Keep in mind, I normally don't do hands-on computer tuning or even deworming. But just as a brain surgeon knows how to set a broken leg, anyone involved in deep computer security knows how to tune preferences and apply patches. In addition, I find it fascinating to see how non-techies use their computers.
Although I repeatedly stated that I'd never touch his computer, I did take pity on his non-technical wife. Her job was to provide tech support since none of his friends want to assist him. While I didn't touch the computer, I did talk her through how to make sure the latest patches were applied and how to turn off Microsoft's "personalized" recommendations and ads. These led to two problems.
First, I have no problem with him having his own political beliefs. The guy has always leaned far right. However, Microsoft's ads and customized recommendations clearly noticed this and were driving him much further to the right. At his wife's request, I showed her how to turn off the customized recommendations in the start menu, in the bottom search bar, in the browser, etc. Immediately his wife noticed that the computer was running much faster.
Second, we used Microsoft Windows 11 to "Check for Updates". Oddly, it was just hanging and not returning anything. After digging through logs, we noticed that he had installed MalwareBytes Antivirus. Twenty years ago, MalwareBytes was a good-enough AV system. However, today it lacks many of the advanced protection features found in other AV systems. (In my opinion, you're better off using the default Windows Defender on Windows 11 than using MalwareBytes. Or better yet, switch to Norton or Sophos.) Moreover, Google found over 4 million results for " malwarebytes blocking windows update ". It turns out, this is a known problem. We turned off MalwareBytes and immediately saw a long list of necessary and critical OS patches. It took nearly an hour and three reboots to bring the system up the current patch level. (I don't think the computer had been patched in years.)
Let me say this very clearly: If your antivirus is blocking critical OS updates, then it's not helping you.
With MalwareBytes disabled, the default Windows Defender AV system kicked on. We did a deep scan and everything was clean.
Finally, we looked at the startup applications. He had Spotify running. It started at boot and always ran, playing some far-right propaganda stream. According to his wife, he usually had the speakers turned off because he couldn't figure out how to stop Spotify. I talked her through how to switch it from "always run" to "manual" (starts when needed). Again, the computer seemed much faster.
When I left there, everything was working well. His wife was pleased. And even the computer's owner said that it was much faster. He also noticed that some of the "clutter" (ads and recommendations) were happily gone.
This happiness lasted about 2 weeks. Then he called up furious that he had a virus and he blamed me. What we were able to piece together:
Honestly, some people just can't be helped. Since I'm not able to drop everything and drive a few hundred miles to help him, I suggested that he take the computer to Best Buy's Geek Squad since, if they can't fix the OS, then they can probably help him buy a new computer. (To reiteration: I'm never touching his computer again, even if his family begs me to help. No matter what you do to deter malware, a determined user can always find a way to self-infect.)
It turns out, having browsers update often isn't always a good thing. Users get burnt out after too many updates. And frankly, I can see why. If it isn't the OS, Chrome, or Firefox wanting an update, then it's Adobe, Word, or something else. On Windows, there isn't a centralized update method; every application manages their own updates. As a result, there's always something that wants to be updated. You can easily spend more time doing updates than doing actual work.
Adding to this problem is a lack of convenience. Most programs check for updates when they first start up and then want to install any updates. However, we start the program because we want to start work. Some updates may take minutes or require a system reboot. We don't want to wait for an update to complete before writing or drawing or looking something up. This is a big reason why updates are often skipped. As Person #2 remarked to me, "Why can't it ask me to apply updates when I'm done?"
Windows 10 and 11 are getting better at the convenience issue. They often try to reboot after work hours. (I occasionally enter my office and notice that the Windows computer rebooted itself overnight.) However, Windows displays an annoying popup that asks if you want to "Reboot now or later?" I'm working now -- why are you bothering me with a popup?
While Windows tries to be convenience, other programs are not as considerate. On Linux, I've had web browsers crash on me because 'snap' did an update and I didn't restart the browser fast enough. (If Chromium on Linux tells you to restart the browser, then it's best to drop everything and restart immediately.)
For this user, I often respond to inquiries for simple tasks. The most common request is "I forgot how to attach a file to an email." The tiny paperclip icon is too small for their bad eyes to see and it isn't intuitive for this person. (This is a usability failure, not a user-education issue.) Another request is about directories: "Where did it save the file?" With browsers, downloads go into the download directory, but a "save" from the scanner or word processor goes into whatever directory was last accessed. On Windows, the "last accessed" directory is usually a bad default. It doesn't take much effort to remotely login and point out the attachment button or help them navigate to the folder containing their document.
Using my remote access, I've already disabled all of the personalized ads and recommendations. (This user doesn't do anything with Xbox games. Why does Windows require Xbox to be enabled?) However, as a remote user, I never noticed something that was really obvious the first time I sat at the keyboard: the computer was slow. When accessing it over the network, I just assumed that any delays were due to the network. Nope -- it was really the computer. The hard drive was constantly grinding.
While visiting in person, I went over the system settings and startup applications. As far as I could tell, Adobe, the AV, and some other apps were looking for updates. Two of the processes were causing an update loop: one checks for updates and the other thinks something changed. Then the second process checks for whatever changed and the first process thinks it needs to check the system again. This was a loop due to battling update systems.
I changed the Adobe and Chrome "check for updates" background programs from automatic to manual. This broke the loop. (Both still check for updates when you run each program. But they no longer check for updates all the time in the background.) Suddenly the computer was significantly faster and the grinding on the hard drive stopped.
Because of these issues, the software was teaching users the wrong things:
Person #1: Self-Inflicted Wounds
The first person I assisted was someone who I swore long ago to never assist. Why? Because things always go wrong on his computer. He seems to get a new computer virus ever few months. He frequently responds to spam messages, and he can't stop clicking on popup ads. The problem is blame: if you touched his computer recently, then the next problem is your fault -- even if it isn't your fault.Although I repeatedly stated that I'd never touch his computer, I did take pity on his non-technical wife. Her job was to provide tech support since none of his friends want to assist him. While I didn't touch the computer, I did talk her through how to make sure the latest patches were applied and how to turn off Microsoft's "personalized" recommendations and ads. These led to two problems.
First, I have no problem with him having his own political beliefs. The guy has always leaned far right. However, Microsoft's ads and customized recommendations clearly noticed this and were driving him much further to the right. At his wife's request, I showed her how to turn off the customized recommendations in the start menu, in the bottom search bar, in the browser, etc. Immediately his wife noticed that the computer was running much faster.
Second, we used Microsoft Windows 11 to "Check for Updates". Oddly, it was just hanging and not returning anything. After digging through logs, we noticed that he had installed MalwareBytes Antivirus. Twenty years ago, MalwareBytes was a good-enough AV system. However, today it lacks many of the advanced protection features found in other AV systems. (In my opinion, you're better off using the default Windows Defender on Windows 11 than using MalwareBytes. Or better yet, switch to Norton or Sophos.) Moreover, Google found over 4 million results for " malwarebytes blocking windows update ". It turns out, this is a known problem. We turned off MalwareBytes and immediately saw a long list of necessary and critical OS patches. It took nearly an hour and three reboots to bring the system up the current patch level. (I don't think the computer had been patched in years.)
Let me say this very clearly: If your antivirus is blocking critical OS updates, then it's not helping you.
With MalwareBytes disabled, the default Windows Defender AV system kicked on. We did a deep scan and everything was clean.
Finally, we looked at the startup applications. He had Spotify running. It started at boot and always ran, playing some far-right propaganda stream. According to his wife, he usually had the speakers turned off because he couldn't figure out how to stop Spotify. I talked her through how to switch it from "always run" to "manual" (starts when needed). Again, the computer seemed much faster.
When I left there, everything was working well. His wife was pleased. And even the computer's owner said that it was much faster. He also noticed that some of the "clutter" (ads and recommendations) were happily gone.
This happiness lasted about 2 weeks. Then he called up furious that he had a virus and he blamed me. What we were able to piece together:
Honestly, some people just can't be helped. Since I'm not able to drop everything and drive a few hundred miles to help him, I suggested that he take the computer to Best Buy's Geek Squad since, if they can't fix the OS, then they can probably help him buy a new computer. (To reiteration: I'm never touching his computer again, even if his family begs me to help. No matter what you do to deter malware, a determined user can always find a way to self-infect.)
Person #2: Technical Enough
One of the people I visited isn't a techie, but is very computer literate. (And having hung around me, this person knows enough about computer security to have developed some very good habits.) Again, I started with applying system patches. (Good news: The OS was up to date!) However, the web browsers (Firefox and Chrome) were behind by a couple of updates.It turns out, having browsers update often isn't always a good thing. Users get burnt out after too many updates. And frankly, I can see why. If it isn't the OS, Chrome, or Firefox wanting an update, then it's Adobe, Word, or something else. On Windows, there isn't a centralized update method; every application manages their own updates. As a result, there's always something that wants to be updated. You can easily spend more time doing updates than doing actual work.
Adding to this problem is a lack of convenience. Most programs check for updates when they first start up and then want to install any updates. However, we start the program because we want to start work. Some updates may take minutes or require a system reboot. We don't want to wait for an update to complete before writing or drawing or looking something up. This is a big reason why updates are often skipped. As Person #2 remarked to me, "Why can't it ask me to apply updates when I'm done?"
Windows 10 and 11 are getting better at the convenience issue. They often try to reboot after work hours. (I occasionally enter my office and notice that the Windows computer rebooted itself overnight.) However, Windows displays an annoying popup that asks if you want to "Reboot now or later?" I'm working now -- why are you bothering me with a popup?
While Windows tries to be convenience, other programs are not as considerate. On Linux, I've had web browsers crash on me because 'snap' did an update and I didn't restart the browser fast enough. (If Chromium on Linux tells you to restart the browser, then it's best to drop everything and restart immediately.)
Person #3: Remote Support
I and one other person often provide remote support for one of my non-technical friends. We have a small Linux box sitting inside their firewall. Either of us can use secure shell (ssh) to log into it and then tunnel VNC to the user's desktop. This is a simple way to provide "remote hands" support.For this user, I often respond to inquiries for simple tasks. The most common request is "I forgot how to attach a file to an email." The tiny paperclip icon is too small for their bad eyes to see and it isn't intuitive for this person. (This is a usability failure, not a user-education issue.) Another request is about directories: "Where did it save the file?" With browsers, downloads go into the download directory, but a "save" from the scanner or word processor goes into whatever directory was last accessed. On Windows, the "last accessed" directory is usually a bad default. It doesn't take much effort to remotely login and point out the attachment button or help them navigate to the folder containing their document.
Using my remote access, I've already disabled all of the personalized ads and recommendations. (This user doesn't do anything with Xbox games. Why does Windows require Xbox to be enabled?) However, as a remote user, I never noticed something that was really obvious the first time I sat at the keyboard: the computer was slow. When accessing it over the network, I just assumed that any delays were due to the network. Nope -- it was really the computer. The hard drive was constantly grinding.
While visiting in person, I went over the system settings and startup applications. As far as I could tell, Adobe, the AV, and some other apps were looking for updates. Two of the processes were causing an update loop: one checks for updates and the other thinks something changed. Then the second process checks for whatever changed and the first process thinks it needs to check the system again. This was a loop due to battling update systems.
I changed the Adobe and Chrome "check for updates" background programs from automatic to manual. This broke the loop. (Both still check for updates when you run each program. But they no longer check for updates all the time in the background.) Suddenly the computer was significantly faster and the grinding on the hard drive stopped.
Common Problems
While people in the computer security field usually don't have these problems, I saw at least one problem on every single non-technical user's system: constant updates, series of prompts, and software that -- even with constant update checks -- were not being updated. In my opinion, this isn't a user-problem. The bad default settings and constant update checks were design decisions that result in usability issues.Because of these issues, the software was teaching users the wrong things:
Značky: #Forensics, #Network, #Security


Enlarge / Ruth Marie Terry, aka the "Lady of the Dunes," in the 1960s. The FBI has identified her killer as her husband, Guy Muldavin. (credit: Courtesy of FBI)
{kind=link}
Last year, after nearly 50 years, the FBI finally identified the murdered woman known as the "Lady of the Dunes," found in Provincetown, Massachusetts, in 1974: Ruth Marie Terry. And now the Massachusetts State Police have officially closed the case after identifying her killer : Terry's husband, Guy Rockwell Muldavin, who died in Salinas, California, in 2002.
As previously reported , a 12-year-old chasing after her barking dog discovered the mutilated body of a woman in the Race Point Dunes of Provincetown, Massachusetts, on July 26, 1974. The body was badly decomposed, with insect activity indicating she had been dead for about two weeks. She was nearly decapitated from a brutal strangulation, but the cause of death was blunt force trauma to the side of the head.
There was no sign of a struggle, but there was evidence of sexual assault that likely occurred after death. In fact, it seems that her attacker had been lying next to her, based on the angle of the blow to the head. Both her hands and one forearm were missing, and several teeth had been removed. Her last meal consisted of a burger and fries. Her body was buried at St. Peter's Cemetery near the center of town, with an inscription on a small gravestone: "Unidentified female body found Race Point dunes July 26, 1974."
Ever since I've moved my servers into my own hosting environment, I've been working on improving the system monitoring. I'm not just watching for
indicators of a network attack
. I'm also preemptively looking for things that could impact the hardware lifespan and operating conditions.
Inside my machine room, I now have tools that actively monitor the network usage, server temperatures, fans, etc. I know when it begins to get too hot or when there is an abnormally high load. Besides alerting me to these issues, the servers automatically manage the common problems. (High heat? Turn on the air conditioner. High load? Increase resources or split the load between systems. This is all completely automated.)
Tracking the system status is easy. Each server has an internal network interface with a web server. A client on the inside of my network can query the web interface for information about the system's load, disk space, network usage, temperature, etc. I've even defined acceptable ranges and color coded them. At a quick glance, anything not 'green' (acceptable) stands out.
My internal web status page displays each server's information. For example:
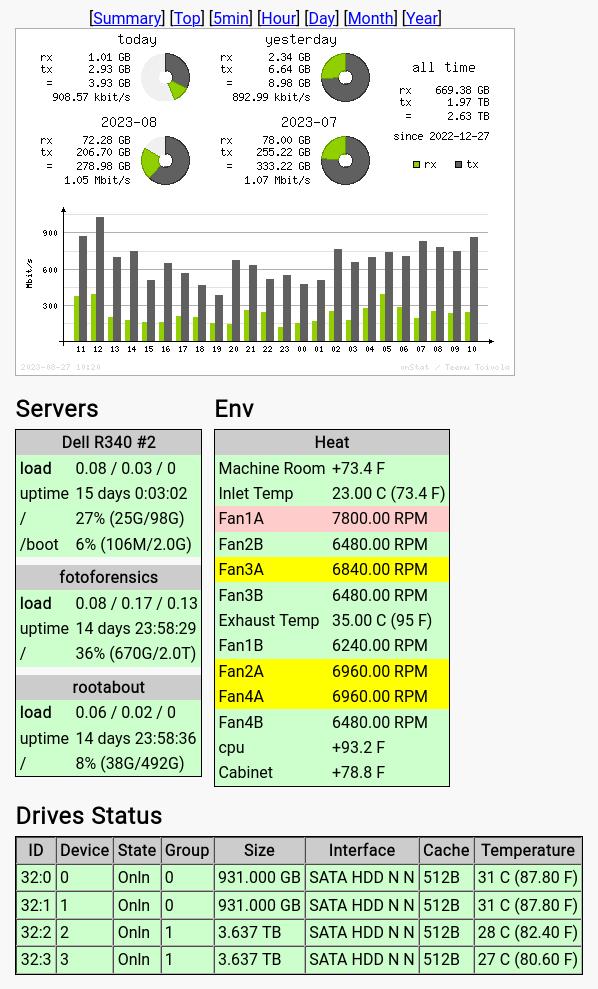
All of my web servers are virtual machines running on different physical servers. At a glance, I can view:
Ideally, I want to have my own external weather station. But for now, I'm harvesting data from public sources.
For my web interface, I color-coded the values. The air quality uses similar colors to the official quality levels. The temperature goes from -40F (-40C; blue) to room temperature (white) to 100F (38C; red) and precipitation (rain/snow) goes from 0% (white) to 100% (blue). Now, with a glance, I can tell how I should plan out the day or week for the upcoming forecast.
I still need to integrate data from lightning strikes (is an electrical storm heading in my direction?), tornado warnings, blizzard notices (stock the office with food for whoever pulls the on-site shift), hail (move your car!), and other extreme events. But this is a good start.
However, there's a trade-off between off-the-shelf and homemade solutions:
Each time I add a new sensor and monitoring rule, I look back and think "why didn't I do this earlier?" Using a primitive prediction system that watches the outside temperature, inside temperature, and server loads, I've been able to cut my AC usage in half. (Air conditioning is a big percent of my electric bill.) I plan to add more sensors to better monitor everything from airflow to water usage. I might even put a smart light with a motion detector in the rack. (It's pretty dark in there.) It's not that I want a "smart home" for my office, but that's the direction this development effort seems to be taking.
Inside my machine room, I now have tools that actively monitor the network usage, server temperatures, fans, etc. I know when it begins to get too hot or when there is an abnormally high load. Besides alerting me to these issues, the servers automatically manage the common problems. (High heat? Turn on the air conditioner. High load? Increase resources or split the load between systems. This is all completely automated.)
Tracking the system status is easy. Each server has an internal network interface with a web server. A client on the inside of my network can query the web interface for information about the system's load, disk space, network usage, temperature, etc. I've even defined acceptable ranges and color coded them. At a quick glance, anything not 'green' (acceptable) stands out.
My internal web status page displays each server's information. For example:
All of my web servers are virtual machines running on different physical servers. At a glance, I can view:
More Monitoring!
Since my health issues last month, I've been more conscious about air quality -- both in the office and outside. One of my servers now monitors the outside environment and compares it to the office. This tells me when I should turn on the HEPA filter or when it's safe to open a window. (We've had so many "bad air quality" alerts this year that I haven't yet opened the window in my office.)Ideally, I want to have my own external weather station. But for now, I'm harvesting data from public sources.
For my web interface, I color-coded the values. The air quality uses similar colors to the official quality levels. The temperature goes from -40F (-40C; blue) to room temperature (white) to 100F (38C; red) and precipitation (rain/snow) goes from 0% (white) to 100% (blue). Now, with a glance, I can tell how I should plan out the day or week for the upcoming forecast.
I still need to integrate data from lightning strikes (is an electrical storm heading in my direction?), tornado warnings, blizzard notices (stock the office with food for whoever pulls the on-site shift), hail (move your car!), and other extreme events. But this is a good start.
DIY or COTS
I know I can get a commercial-off-the-shelf (COTS) solution for watching the weather, temperature, etc. that integrates with Google Nest, Amazon, other other big cloud providers. Their components are certainly less expensive than anything I build. A typical weather station has 4-8 sensors, with another half dozen sensors for air quality. Individually, each sensor costs $25-$35, and still needs you to combine electronics and build a server to receive the data. Or you can get a COTS solution with everything built-in for under $200 .However, there's a trade-off between off-the-shelf and homemade solutions:
Each time I add a new sensor and monitoring rule, I look back and think "why didn't I do this earlier?" Using a primitive prediction system that watches the outside temperature, inside temperature, and server loads, I've been able to cut my AC usage in half. (Air conditioning is a big percent of my electric bill.) I plan to add more sensors to better monitor everything from airflow to water usage. I might even put a smart light with a motion detector in the rack. (It's pretty dark in there.) It's not that I want a "smart home" for my office, but that's the direction this development effort seems to be taking.
Značky: #Programming, #AI, #Forensics, #Network
Don’t do it :
Recently, the manager of the Harvard Med School morgue was accused of stealing and selling human body parts. Cedric Lodge and his wife Denise were among a half-dozen people arrested for some pretty grotesque crimes . This part is also at least a little bit funny though:
Over a three-year period, Taylor appeared to pay Denise Lodge more than $37,000 for human remains. One payment, for $1,000 included the memo “head number 7.” Another, for $200, read “braiiiiiins.”
It’s so easy to think that you won’t get caught.
Along with my production servers, like
FotoForensics
,
Hintfo
, and this blog, I run a bunch of honeypot systems. These honeypots provide a great baseline for identifying the typical attack levels on the internet. (If you have a system on the internet and you don't think you're being attacked, then you're not watching your logs.)
Honeypots also allow me to run a variety of A/B Tests. Every single network security option deployed on my production sites can be compared to the honeypot results. It's one thing to say "do this to deter attacks", but it's another to have empirical data that shows the effectiveness of the deterrence.
It's also common to hear sysadmins say that they implement some security feature because of "best practices" or "conventional wisdom". With data from my honeypots, I've learned that some of these "best practices" and heuristics from "conventional wisdom" are wrong or suboptimal.
Even with all of the address ranges allocated, it doesn't mean every address is in use. Subnets require reserved gateway and broadcast addresses. ISPs have blocks of network addresses just waiting for allocation to customers, and companies often reserved addresses for future use. So how does an attacker find a system to attack?
ICMP echo request (aka 'ping') packets are often used for discovery attacks. An attacker with a gigabit connection can ping all of IPv4 in a few hours. (There are other scanning techniques that can do it even faster.) The attacker sends out a bunch of ping packets and listens for the responses. If nothing comes back, then they assume that the address is not in use (or the server is not an easy target) and they move on. If they receive any kind of reply, then they know there is a server at that address and they can schedule the address for deeper scans and a myriad of attacks.
"Best practices" says to block ping packets in order to reduce network scans. Many people disable ping because they have subjective experience that it can be effective at deterring network attacks.
As a test, I deployed a few honeypots. Some of them always responded to ping packets and some never respond. In addition, all of the honeypots include web servers that were receiving a variety of scans and attacks. (Typical web attack noise levels.) The result? Servers that do not respond to ping packets will see 90% fewer pings and 80% fewer web attacks. Switching one of my "ping reply" honeypots to "ping block" shows that you can see the attack levels decline within hours and reach the expected lower volume within a week.
(Keep in mind, these are the results from this year. In another few years, it might be very different.)
This little experiment shows that "best practices" and "conventional wisdom" are correct: if you run an online service, then you really should block ICMP echo request packets.
As the sheer number of available network addresses goes, IPv6 is mindbogglingly massive compared to IPv4.
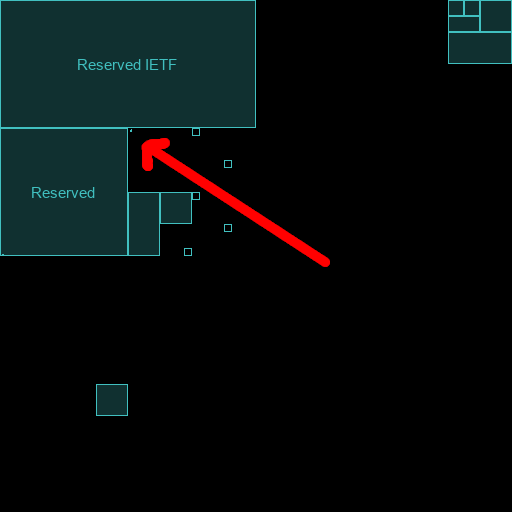
This is a Hilbert graph that represents all of the IPv6 address space. The image is 512x512 pixels and each pixel represents a "/18" subnet. Each pixel represents a network range that is over three hundred sextillion times larger (2 78 ) than all of IPv4. The rectangular blocks identify the reserved address spaces. The rest of IPv6 is unallocated.
I drew in a red arrow that points to a small cluster of dots in one corner. Those dots are the allocated IPv6 space, and even those dots are extremely sparsely allocated. It's not practical to scan for every IPv6 address for possible servers. On my honeypots, I was seeing zero IPv6 traffic, even though the servers were configured for IPv6.
I ended up needing to give the attackers a hint so that they could find my honeypots over IPv6.
Here's the truth:
On the other hand, with IPv4, blocking ping caused the number of ping scans to drop by 90%. With IPv6, I've seen no impact to the number of pings over IPv6, even if my server is configured to not respond. This table shows the last 3 weeks of recorded packet scans from one of my honeypots that does not respond to any ping packets:
If I respond to IPv4 ping packets, then I can receive 1-2 million pings in 3 weeks. Blocking ping over IPv4 reduces it to a few hundred thousand ping attempts. In contrast, regardless of whether I block or respond to IPv6 ping packets, I'm seeing nearly a million pings every 3 weeks.
The conventional wisdom does not hold for IPv6 ping packets. Blocking ping does not break IPv6 and it doesn't reduce the number of ping scans. However, it does reduce the number of TCP scans after the attacker discovers the server with IPv6 ping.
Spam is one of the oldest online scam methods out there. As bad as their emails might read, today's spammers are very sophisticated and always looking for new ways to send their emails. The spam methods used today are not the same as the methods used 10, 20, or 30 years ago.
When configuring a new mail server, "best practices" and "conventional wisdom" tell you to configure it to only accept email for known accounts at your specific domain(s). Everything else should be rejected by the mail server. This configuration is so common that it is default for most mail server software. Today, spammers test the mail server and see that it rejects unknown domains. This tells them that it's a configured mail server. They will then iterate though every possible account name at your domain in an attempt to discover a potential recipient. My mail logs are filled with "user unknown" rejection messages like these:
In contrast, a honeypot's mail server is often configured to receive all email but send nothing. My honeypot currently receives 1-3 test emails from spammers every day, as they check to see if the server is configured (rejecting) or relaying (accepting all). The test emails often look like:
What I've learned is that spammers detect this situation and leave honeypots alone. This honeypot has been running with this configuration for nearly 6 months. In the last 3 weeks, it has received 60 test emails, 1,875 attempts to relay without sending any emails (a quick litmus test used by the spammers and other attackers), and ZERO spam messages. By comparison, my production server rejects unknown recipients and has received a few thousand email attempts from spammers during the same timeframe. The known accounts receive a few dozen spam messages per day -- and that's with SPF and DKIM checking enabled. As another test, I reconfigured one of my production servers to accept all email but send unknown recipients to a spam folder. After a week, the volume began to drop.
The conventional wisdom says to reject any emails that are not addressed to specific accounts at your domain. However, the more effective anti-spam solution today is to accept all email but only deliver emails to the specific accounts at your domain. Everything else can go into a spam folder or sinkhole or /dev/null. This way, spammers will think that your regular mail server is actually a honeypot and they will avoid it.
"Best practices" and "conventional wisdom" provide good initial heuristics for locking down a system. However, it's also good to periodically re-evaluate these assumptions. Sometimes the "best practices" are not always best.
Honeypots also allow me to run a variety of A/B Tests. Every single network security option deployed on my production sites can be compared to the honeypot results. It's one thing to say "do this to deter attacks", but it's another to have empirical data that shows the effectiveness of the deterrence.
It's also common to hear sysadmins say that they implement some security feature because of "best practices" or "conventional wisdom". With data from my honeypots, I've learned that some of these "best practices" and heuristics from "conventional wisdom" are wrong or suboptimal.
Ping Ping Ping
The internet is a big place. IPv4 has about 3.7 billion usable network addresses. (That's 4.3 billion total addresses, excluding loopback, private ranges, broadcast ranges, etc.) Considering that there are about 7.9 billion people on Earth, that's not enough addresses to go around. Furthering the scarcity, the address ranges have not been handed out evenly. The IPv4 exhaustion problem began in 2010 and completed in 2019. Today, there are no freely available IPv4 address ranges. (If you want a new IPv4 address range, someone else needs to give it up.)Even with all of the address ranges allocated, it doesn't mean every address is in use. Subnets require reserved gateway and broadcast addresses. ISPs have blocks of network addresses just waiting for allocation to customers, and companies often reserved addresses for future use. So how does an attacker find a system to attack?
ICMP echo request (aka 'ping') packets are often used for discovery attacks. An attacker with a gigabit connection can ping all of IPv4 in a few hours. (There are other scanning techniques that can do it even faster.) The attacker sends out a bunch of ping packets and listens for the responses. If nothing comes back, then they assume that the address is not in use (or the server is not an easy target) and they move on. If they receive any kind of reply, then they know there is a server at that address and they can schedule the address for deeper scans and a myriad of attacks.
"Best practices" says to block ping packets in order to reduce network scans. Many people disable ping because they have subjective experience that it can be effective at deterring network attacks.
As a test, I deployed a few honeypots. Some of them always responded to ping packets and some never respond. In addition, all of the honeypots include web servers that were receiving a variety of scans and attacks. (Typical web attack noise levels.) The result? Servers that do not respond to ping packets will see 90% fewer pings and 80% fewer web attacks. Switching one of my "ping reply" honeypots to "ping block" shows that you can see the attack levels decline within hours and reach the expected lower volume within a week.
(Keep in mind, these are the results from this year. In another few years, it might be very different.)
This little experiment shows that "best practices" and "conventional wisdom" are correct: if you run an online service, then you really should block ICMP echo request packets.
Scanning IPv6
However, that experiment is based on IPv4. Today, every mobile phone uses IPv6. Many countries are primarily on IPv6 and about 40% of the global internet supports IPv6 traffic.As the sheer number of available network addresses goes, IPv6 is mindbogglingly massive compared to IPv4.
This is a Hilbert graph that represents all of the IPv6 address space. The image is 512x512 pixels and each pixel represents a "/18" subnet. Each pixel represents a network range that is over three hundred sextillion times larger (2 78 ) than all of IPv4. The rectangular blocks identify the reserved address spaces. The rest of IPv6 is unallocated.
I drew in a red arrow that points to a small cluster of dots in one corner. Those dots are the allocated IPv6 space, and even those dots are extremely sparsely allocated. It's not practical to scan for every IPv6 address for possible servers. On my honeypots, I was seeing zero IPv6 traffic, even though the servers were configured for IPv6.
I ended up needing to give the attackers a hint so that they could find my honeypots over IPv6.
Ping over IPv6
Ping over IPv6 is a little different than ping over IPv4. There are plenty of online documents that warn against blocking IPv6 ping packets (ICMPv6 echo request). Some suggest that it is a bad idea or harmful . Some even say that blocking IPv6 ping will prevent routing over IPv6.Here's the truth:
On the other hand, with IPv4, blocking ping caused the number of ping scans to drop by 90%. With IPv6, I've seen no impact to the number of pings over IPv6, even if my server is configured to not respond. This table shows the last 3 weeks of recorded packet scans from one of my honeypots that does not respond to any ping packets:
| Ping | TCP | UDP | ICMP | GRE | IPv6 | SCTP | Total | TCP/Total | |
|---|---|---|---|---|---|---|---|---|---|
| IPv4 | 204,334 | 392,165 | 9,248 | 76 | 12 | 2 | 1 | 605,838 | 64.73% |
| IPv6 | 936,666 | 7,272 | 632 | 0 | 0 | 0 | 0 | 944,570 | 0.77% |
| IPv4+IPv6 | 1,141,000 | 399,437 | 9,880 | 76 | 12 | 2 | 1 | 1,550,408 | 25.76% |
| IPv6/Total | 82.09% | 1.82% | 6.40% | 0.00% | 0.00% | 0.00% | 0.00% | 60.92% |
If I respond to IPv4 ping packets, then I can receive 1-2 million pings in 3 weeks. Blocking ping over IPv4 reduces it to a few hundred thousand ping attempts. In contrast, regardless of whether I block or respond to IPv6 ping packets, I'm seeing nearly a million pings every 3 weeks.
The conventional wisdom does not hold for IPv6 ping packets. Blocking ping does not break IPv6 and it doesn't reduce the number of ping scans. However, it does reduce the number of TCP scans after the attacker discovers the server with IPv6 ping.
More Bad Advice
Another thing I've learned from my honeypots concerns email and spam. The "best practices" and "conventional wisdom" for configuring a mail server was really good advice a few decades ago. However, it just hasn't held up over time.Spam is one of the oldest online scam methods out there. As bad as their emails might read, today's spammers are very sophisticated and always looking for new ways to send their emails. The spam methods used today are not the same as the methods used 10, 20, or 30 years ago.
When configuring a new mail server, "best practices" and "conventional wisdom" tell you to configure it to only accept email for known accounts at your specific domain(s). Everything else should be rejected by the mail server. This configuration is so common that it is default for most mail server software. Today, spammers test the mail server and see that it rejects unknown domains. This tells them that it's a configured mail server. They will then iterate though every possible account name at your domain in an attempt to discover a potential recipient. My mail logs are filled with "user unknown" rejection messages like these:
The opposite configuration is to accept all emails. My test server had to be shut down after less than an hour because it was very quickly used to relay spam messages to the entire world. The spammers saw an open mail relay and immediately abused it.Jun 14 01:41:20 bit postfix/smtpd[5231]: NOQUEUE: reject: RCPT from prd-bd-4F46V7.cleanmaillist.com[209.250.5.194]: 550 5.1.1 <noistj70no708@hackerfactor.com>: Recipient address rejected: User unknown in local recipient table; from=<D6783A@prd-bd-4F46V7.cleanmaillist.com> to=<noistj70no708@hackerfactor.com> proto=ESMTP helo=<prd-bd-4F46V7.cleanmaillist.com>
Jun 14 03:26:22 bit postfix/smtpd[5769]: NOQUEUE: reject: RCPT from nd2.webitemails.com[185.162.23.250]: 550 5.1.1 <jon183doe989734782@hackerfactor.com>: Recipient address rejected: User unknown in local recipient table; from=<notification@nd2.webitemails.com> to=<jon183doe989734782@hackerfactor.com> proto=ESMTP helo=<nd2.webitemails.com>
Jun 14 13:32:45 bit postfix/smtpd[9675]: NOQUEUE: reject: RCPT from mail.zaksobr-chita.ru[185.108.196.222]: 550 5.1.1 <200610202209.k9km9ki28092@hackerfactor.com>: Recipient address rejected: User unknown in local recipient table; from=<test@zaksobr-chita.ru> to=<200610202209.k9km9ki28092@hackerfactor.com> proto=SMTP helo=<zaksobr-chita.ru>
In contrast, a honeypot's mail server is often configured to receive all email but send nothing. My honeypot currently receives 1-3 test emails from spammers every day, as they check to see if the server is configured (rejecting) or relaying (accepting all). The test emails often look like:
From nouth@{domain} Fri Jun 9 13:08:00 2023
Return-Path: <nouth@{domain}>
Received: from COMPAQ (static-148-244-225-136.alestra.net.mx [148.244.225.136])
by {domain} (Postfix) with ESMTP id B32BF2401BF
for <test@hostxbay.com>; Fri, 9 Jun 2023 13:07:59 -0600 (MDT)
MIME-Version: 1.0
From: "Rose Amag3" <nouth@{domain}>
To: test@hostxbay.com
Date: 9 Jun 2023 13:07:47 -0600
Subject: NOUTH {domain}
Content-Type: text/html; charset=us-ascii
Content-Transfer-Encoding: quoted-printable
~~~{domain},587,nouth,,{domain}|||hhvv
What I've learned is that spammers detect this situation and leave honeypots alone. This honeypot has been running with this configuration for nearly 6 months. In the last 3 weeks, it has received 60 test emails, 1,875 attempts to relay without sending any emails (a quick litmus test used by the spammers and other attackers), and ZERO spam messages. By comparison, my production server rejects unknown recipients and has received a few thousand email attempts from spammers during the same timeframe. The known accounts receive a few dozen spam messages per day -- and that's with SPF and DKIM checking enabled. As another test, I reconfigured one of my production servers to accept all email but send unknown recipients to a spam folder. After a week, the volume began to drop.
The conventional wisdom says to reject any emails that are not addressed to specific accounts at your domain. However, the more effective anti-spam solution today is to accept all email but only deliver emails to the specific accounts at your domain. Everything else can go into a spam folder or sinkhole or /dev/null. This way, spammers will think that your regular mail server is actually a honeypot and they will avoid it.
"Best practices" and "conventional wisdom" provide good initial heuristics for locking down a system. However, it's also good to periodically re-evaluate these assumptions. Sometimes the "best practices" are not always best.
Značky: #Network, #Forensics, #Security, #Programming
It finally happened. Two days ago, the Department of Justice (DOJ) released the 2nd indictment against former president Donald Trump. Almost immediately, I received inquiries about the photos in the indictment and the PDF document. I'm going to address most of these inquiries, but I'm not going to opine on the political, legality, or criminality around the indictment and legal process. I'm strictly looking at the PDFs and pictures.
During the announcement, Smith made the comment "read the indictment". Here's the first problem: where can you find the original source document? Honestly, this was more difficult than I expected. Many news outlets have copies of the document, but a viral copy is not the same as having the original source file. Some of the viral copies have been re-encoded, re-saved, etc. I wanted the original source.
I found two links at the US Department of Justice (justice.gov) web site. The first link ( https://www.justice.gov/opa/speech/special-counsel-jack-smith-delivers-statement ) goes to a written text statement from Jack Smith. In it, he says to "read it in full to understand the scope and the gravity of the crimes charged." However, there is no link to the actual document for reading.
The second link goes to a video statement by Jack Smith: https://www.justice.gov/opa/video/statement-special-counsel-jack-smith Under the video are three links: one to information about Jack Smith, one to the previous written statement, and the third link goes to the PDF containing the indictment! This third link is the authoritative source: https://www.justice.gov/storage/US_v_Trump-Nauta_23-80101.pdf
The document was filed in the State of Florida, so they also have a copy of the indictment: https://www.flsd.uscourts.gov/sites/flsd/files/23-CR-80101-INDICTMENT.pdf . This is also an authoritative source.
Interestingly, these two authoritative sources are different. These differences do not alter the textual content. Instead, they show how the documents were handled.
The key differences between the two authoritative documents?
All of these differences just show how the PDFs were handled. Both of these documents are authoritative because they come from the official sources, even though they have these differences.
These are not the only versions of the document available online. For example, the copy hosted by NBC News ( https://www.nbcnews.com/politics/read-full-indictment-text-classified-document-probe-rcna88600 ) visually looks like the 49-page black-and-white version from flsd.uscourts.gov, but has a different modification date in the metadata; NBC's document was last modified five hours after Florida's version. In contrast, CNN appears to have started with the 44-page justice.gov version, but then they converted each page to a picture. Although the content is visually similar, neither version from these news outlets is an authoritative version. If you want the authoritative version, get it from the authorities: justice.gov and flsd.uscourts.gov.
Although these two version are authoritative, neither PDF is the "original" version of the document. When someone exports a file as a PDF, they typically use default options that re-encode images. This resizes and recolors the images, removes the photo's original metadata, and re-encodes the files at a lower quality. In this case, all of the photos are consistent with pictures last-encoded using an Adobe application, including Adobe Acrobat.
Keep in mind: This does not mean that the government does not have the original photos with complete metadata and proper forensic tracking. It only means that the PDF copy of the original document includes copies of the photos and not the original photos.
Online, you can find viral copies of the photos. However, most people seem to simply take snapshots of the PDF pages and crop down to the photos. In contrast, I used forensic tools to extract the images without further scaling, re-encoding, or other alterations. Here are the extracted images from this document. (Click on any of them to view them at FotoForensics. For inclusion in this blog entry, I've scaled them down.)
If you view the files at FotoForensics, you can click the "[Uploaded Source Image]" link at the bottom of the page to see the full-size image from a forensically-sound extraction of the PDF. These are currently the highest quality versions of the uncropped image that you can find online. Almost every other online version is a viral copy or from a copy of a copy, and some of the variants include post-release alterations.
The image dimensions and artifacts are all consistent with pictures that have been scaled and/or cropped, stripped of metadata, and re-encoded using an Adobe application. I see no indication of digital alterations (adding elements, removing elements, or redactions). This suggests that these images, while potentially cropped or scaled smaller, are representative of the original evidence photos. (However, I would have liked to see the technical evidence summary for evidence handling, including the original checksums, some metadata, and information about the dimensions.)
None of the photos in the PDF have metadata, so the pictures do not identify when they were taken or who took them. However, the descriptions in the indictment make it very clear when these photos were captured and who took the pictures. I see no reason to distrust these images. There is nothing deceptive about how the PDFs, or included images, were handled.
Often I blog about cases where information was altered. It felt refreshing to do an analysis where things are exactly as they appear.
Acquiring the PDF
The indictment release was part of a public announcement made by Special Counsel Jack Smith. It was covered by almost every major news outlet.During the announcement, Smith made the comment "read the indictment". Here's the first problem: where can you find the original source document? Honestly, this was more difficult than I expected. Many news outlets have copies of the document, but a viral copy is not the same as having the original source file. Some of the viral copies have been re-encoded, re-saved, etc. I wanted the original source.
I found two links at the US Department of Justice (justice.gov) web site. The first link ( https://www.justice.gov/opa/speech/special-counsel-jack-smith-delivers-statement ) goes to a written text statement from Jack Smith. In it, he says to "read it in full to understand the scope and the gravity of the crimes charged." However, there is no link to the actual document for reading.
The second link goes to a video statement by Jack Smith: https://www.justice.gov/opa/video/statement-special-counsel-jack-smith Under the video are three links: one to information about Jack Smith, one to the previous written statement, and the third link goes to the PDF containing the indictment! This third link is the authoritative source: https://www.justice.gov/storage/US_v_Trump-Nauta_23-80101.pdf
The document was filed in the State of Florida, so they also have a copy of the indictment: https://www.flsd.uscourts.gov/sites/flsd/files/23-CR-80101-INDICTMENT.pdf . This is also an authoritative source.
Interestingly, these two authoritative sources are different. These differences do not alter the textual content. Instead, they show how the documents were handled.
The key differences between the two authoritative documents?
| justice.gov | flsd.uscourts.gov |
|---|---|
| The PDF is 44 pages long. It only contains the indictment. | The PDF is 49 pages long. The first 44 pages are the indictment. The remaining 5 pages appear to be additional filing instructions regarding the related penalties for the different identified crimes. |
| Page 44 includes a red stamp that says it was filed with the U.S. District Court. | Page 44 is missing this stamp. This means that this copy of the document was not received by the same office as justice.gov. |
| This document does not have any extra text added to the pages. |
There is a blue header at the top of each page that provides the case, document, docket, and page number (the Bates identifier)
Legal documents are tracked using " Bates Numbering ". Every piece of evidence in a case, including every page of a document, includes a unique identifier. This way, the attorneys can reference the Bates identifier and everyone sees the same thing. |
| Almost every page of text is actual text. You can easily select the text in order to copy it to another document. The first and last pages are available as actual text and as a picture of text. The pictures are used to capture the various filing stamps, Smith's signature, and the final redacted name. | Every page is a picture of text. Unless your PDF viewer supports real-time OCR, you cannot select any text except for the blue filing information at the top of each page. |
The text appears to have been generated by an optical character recognition (OCR) system built into the scanner. I say this because there are a couple of places where it appears that the OCR poorly translated the document. For example, on page 44, the image of the red stamp visually looks correct, but the selected text says:
Similarly, the last sentence on page 44 cites "Title 18, United States Code, Section 100l(a)(2)." That's "100" followed by a lowercase "L", and not one thousand one. On page 28, the table for count 2 shows the word "January", but selecting the text shows "Janua1y". There are also some places where "military" is spelled "milita1y" and "February" is spelled "Febma1y". Confusing the number "1" for a lowercase "L", zero with the letter "O", and odd spelling errors are common OCR mistakes. If you're going to copy text out of this document, make sure everything is spelled correctly. (Don't assume the OCR spelled everything correctly.) | No OCR was used, but every page is a picture of text. |
| A few pages contain color photos. | All photos are in black and white (not even grayscale). This is probably due to someone standing over a photocopier and using the black-and-white setting, or transmitted the document as a "FAX". (Although the legal system still uses fax machines, I don't see noise artifacts that are typically associated with faxed documents. However, the image encoding uses a filter called "CCITTFaxDecode". Someone probably saved it for faxing, but transmitted it via email or some other higher-quality method.) |
| The link to the PDF document says the PDF is from June 8, 2023. However, the PDF metadata says the file was created on Fri Jun 9 17:08:33 2023 GMT. | The PDF metadata says the file was created on Jun 8 20:44:52 2023 GMT. |
| The PDF contains no indication of alteration or modification after being initially generated. | The PDF file structure uses objects (data blocks) to define text, fonts, images, etc. This PDF contains 3 unused objects: 294 (an XREF), 401, and 415. The unused objects indicate that the PDF was edited after it was initially generated. |
| The PDF was generated using Adobe Acrobat Pro (32-bit) 23 Paper Capture Plug-in. | The PDF was generated using iText 7.1.6 2000-2019 iText Group NV (Administrative Office of the United States Courts; licensed version) and then modified using iText 7.1.6 2000-2019 iText Group NV (Administrative Office of the United States Courts; licensed version) |
All of these differences just show how the PDFs were handled. Both of these documents are authoritative because they come from the official sources, even though they have these differences.
These are not the only versions of the document available online. For example, the copy hosted by NBC News ( https://www.nbcnews.com/politics/read-full-indictment-text-classified-document-probe-rcna88600 ) visually looks like the 49-page black-and-white version from flsd.uscourts.gov, but has a different modification date in the metadata; NBC's document was last modified five hours after Florida's version. In contrast, CNN appears to have started with the 44-page justice.gov version, but then they converted each page to a picture. Although the content is visually similar, neither version from these news outlets is an authoritative version. If you want the authoritative version, get it from the authorities: justice.gov and flsd.uscourts.gov.
Evaluating Pictures
The photos in the indictment are one of the more interesting aspects. The flsd.uscourts.gov document converted the pictures to two-tone black-and-white. That makes them effectively worthless for any kind of digital analysis. In contrast, the justice.gov version contains full-color photos.Although these two version are authoritative, neither PDF is the "original" version of the document. When someone exports a file as a PDF, they typically use default options that re-encode images. This resizes and recolors the images, removes the photo's original metadata, and re-encodes the files at a lower quality. In this case, all of the photos are consistent with pictures last-encoded using an Adobe application, including Adobe Acrobat.
Keep in mind: This does not mean that the government does not have the original photos with complete metadata and proper forensic tracking. It only means that the PDF copy of the original document includes copies of the photos and not the original photos.
Online, you can find viral copies of the photos. However, most people seem to simply take snapshots of the PDF pages and crop down to the photos. In contrast, I used forensic tools to extract the images without further scaling, re-encoding, or other alterations. Here are the extracted images from this document. (Click on any of them to view them at FotoForensics. For inclusion in this blog entry, I've scaled them down.)
| Page 10: | ||
| Page 12: | ||
| Page 13 top: | (You might notice that this version has the proper aspect ratio. The PDF document changed the aspect ratio during the page rendering, making the picture look squashed.) | |
| Page 13 bottom: | ||
| Page 14: | ||
| Page 16: |
If you view the files at FotoForensics, you can click the "[Uploaded Source Image]" link at the bottom of the page to see the full-size image from a forensically-sound extraction of the PDF. These are currently the highest quality versions of the uncropped image that you can find online. Almost every other online version is a viral copy or from a copy of a copy, and some of the variants include post-release alterations.
The image dimensions and artifacts are all consistent with pictures that have been scaled and/or cropped, stripped of metadata, and re-encoded using an Adobe application. I see no indication of digital alterations (adding elements, removing elements, or redactions). This suggests that these images, while potentially cropped or scaled smaller, are representative of the original evidence photos. (However, I would have liked to see the technical evidence summary for evidence handling, including the original checksums, some metadata, and information about the dimensions.)
None of the photos in the PDF have metadata, so the pictures do not identify when they were taken or who took them. However, the descriptions in the indictment make it very clear when these photos were captured and who took the pictures. I see no reason to distrust these images. There is nothing deceptive about how the PDFs, or included images, were handled.
Often I blog about cases where information was altered. It felt refreshing to do an analysis where things are exactly as they appear.
Značky: #Forensics, #FotoForensics, #Network, #Politics
Disclaimer and content warning
: This blog entry discusses the reporting of child pornography. If you are sensitive to that topic, then stop reading now. Also, I reference a number of Federal laws. However, I am not a lawyer, this is my non-lawyer understanding, and nothing I say should be taken as legal advice.
The National Center for Missing and Exploited Children ( NCMEC ) is tasked by Congress to be the national clearinghouse for handling information related to child sexual abuse. NCMEC coordinates with the FBI, US Customs, US Secret Service, US Postal Inspectors, and other law enforcement organizations in order to handle reports from online service providers (Electronic Service Providers, or ESPs).
As someone who provides online services (including FotoForensics , RootAbout , and Hintfo ), the law defines me as an ESP and requires me to be a mandatory reporter for child pornography (CP) on my sites. As noted in 18 U.S. Code § 2258A , if I see child pornography then I must report it to NCMEC's CyberTipline. The reports go from me (and every other ESP) to NCMEC's CyberTipline to any of the Internet Crimes Against Children (ICAC) locations (there's at least one ICAC per state) to local law enforcement. The flow from NCMEC to law enforcement isn't always this lock-step since " FBI personnel assigned to the NCMEC review information that is provided to NCMEC's CyberTipline". (The ESP's CyberTip may go straight to the FBI.)
Since 2019, NCMEC has been releasing a "by the numbers" summary that lists the number of reports per ESP. They just posted the 2022 report last week. Although NCMEC's list is alphabetical, I typically sort it by volume of reports. Here's the top ten ESP reporters for the last few years:
The numbers and names don't match exactly every year. For example, the 2019 "Facebook" was all of Facebook, but 2021 and 2022 separated out Meta's services into Facebook, Instagram, and WhatsApp. (No matter how you slice it, over 90% of reports to NCMEC come from Facebook/Meta.) Similarly, the name "Microsoft" sometimes refers to all of their online properties and sometimes separate properties like "Xbox" and "Online Operations" have their own entries.
The increase from Reddit suggests that they are being more effective at detecting and reporting it. (I'm sure that the 2021 lawsuit alleging that Reddit was profiting from CP also resulted in changes to their detection and reporting.) Similarly, the change in volume from Discord coincides with a change in their terms of service (compare March 2021 against December 2021 ).
One thing to keep in mind is that every company that hosts other people's uploaded pictures should be a registered ESP. However, the number of registered ESPs at NCMEC really doesn't represent every possible ESP.
*
Includes company splits, such as when Meta changed from reporting as "Facebook" (one ESP) to reporting as Facebook, Instagram, and WhatsApp (3 ESPs).
Frankly, there should be a lot more ESPs reporting. The 31 million total reports in 2022 does not come from very many companies. Every single Mastodon service provider should be registered. (I doubt there is zero CP on all of Mastodon.) Every porn site should be registered. Tumblr didn't start reporting until 2021. MailChimp had their first (and only) report in 2022.
The amount of cooperation from ESPs varies. In my subjective view, ESPs can be divided into four categories:
Probably the biggest example of an uncooperative company is Apple.
Every year, I report to more CP sightings to NCMEC's CyberTipline than Apple. It isn't that I receive more pictures than Apple or that Apple doesn't receive as much CP. Rather, I think that Apple just doesn't like to report it. Back in 2021, Apple announced a controversial system for automatically detecting CP on user's devices. After much criticism, Apple decided to indefinitely postpone the release. Later, in December 2021, Apple decided to roll out part of their automated detection . As I sarcastically remarked last year , "I certainly expected Apple to submit more than 160 reports to NCMEC." Well, they did, but barely. This certainly isn't the kind of volume I'd expected from an automated detection system.
Rather, Apple seems to be intentionally not reporting. As Apple's SVP Craig Federighi noted in 2021 , Apple uses arbitrary thresholds. Federighi remarked that Apple only looks at the content if their iCloud receives something like 30 flagged files from a user's account. The problem is, 18 USC 2258A says that every ESP has a "Duty To Report" (2258A(a)) and that knowing and willfully failing to report is a felony (2258A(e)). The law doesn't stipulate any thresholds for reporting; if an ESP sees CP then they must report it. For me, some of my reports include multiple pictures, but others only include single sightings. So why can Apple get away with arbitrary thresholds when I have to report everything? That's easy: they have more attorneys.
Then again, there could be another explanation. As I understand it, 18 USC 2252 makes it illegal to intentionally search for CP. This includes searching your own system. Most ESPs have services that forbid general topics, like "no porn". If, while filtering out porn, they encounter CP, then they must report it ( 2258A , mandatory reporting). However, the telecommunication companies (Verizon, AT&T, etc.) don't have any such restrictions, so they can't unintentionally encounter CP while filtering out something else. On the other hand, Apple includes warnings about prohibited content and has mentioned a desire to scan user's content , so I can't see them being able to use this excuse.
Personally, I'm guilty of using NCMEC this way. If a picture might be CP, then I submit it because I don't want to spend any time evaluating it. Also, 18 USC 2252 makes it illegal to "knowingly accesses with intent to view", so any detailed evaluation before sending it to the CyberTipline could be illegal. I assume (and hope) that someone at NCMEC, at an ICAC, or in law enforcement will tell me if one of my submissions isn't CP. But in 10 years, that's only happened once.
The best example here is Meta (formerly Facebook; includes Facebook, Instagram, and WhatsApp).
Over the years, I have repeatedly asked NCMEC for a copy of one of my reports -- just to see what the data going in looks like when it comes out. NCMEC runs a test server for ESPs to develop their submission methods (never upload real CP to the test server), but I can't even get a copy of a report from that. I've had NCMEC employees tell me that they can generate a test report for me from the test server, but when I run the test submission, they never respond to the request for the test report. (This has been going on for years.)
Having said that, I've seen a few dozen CyberTipline reports generated by NCMEC, including one of my own. (NCMEC never provided them directly to me and I wasn't allowed to keep a copy of my own report.) These have included reports from Google ( example 1 , example 2 ), Facebook, and a handful of other ESPs. Google's reports don't usually have obvious errors. However in my experience, every single report from Meta (and Facebook before that) has been filled out wrong . Some of the errors are really basic (like the failing to read NCMEC's documentation and providing the wrong data), while others misrepresent information. (I can't tell if it's malicious or incompetence, so let's assume the latter.) In any case, Meta accounts for over 90% of submissions to NCMEC (87% in 2022), so over 90% of those CyberTips to NCMEC are effectively junk. (If you're law enforcement and working with a Meta CyberTipline report, just assume that the chain of custody is broken.)
Keep in mind, NCMEC doesn't validate the information from the ESPs. They just receive it, correlate and combine it with other reports, and forward it to law enforcement (FBI, ICAC, etc.). NCMEC is a clearinghouse and not a validation center. The assumption is that law enforcement will see any errors or incomplete information and decide how to handle the data. However, that's never what happens. In my experience, if law enforcement can misinterpret the data, then they will misinterpret it.
Also, the high volume of junk submissions from Meta doesn't hurt NCMEC. If anything, it helps them justify to Congress and the Department of Justice why NCMEC needs additional funding each year.
I did mention that Meta has errors in their reports. Unfortunately, that is sometimes the case for reports from other ESPs. However, the quantity and quality of errors are rarely as bad as Meta. (If NCMEC provided sample reports back to the ESPs for validating their submission process, then most of these errors could be corrected pretty quickly.)
Having said that, every year I try to improve my detection and reporting process. I've learned that the faster I detect and block the offenders, the fewer offenders I receive. As a result, I've seen a drop in the number of CP reports that I've needed to submit to the CyberTipline:
My big drop from 2020 to 2021 was because I cut off all of Russia from using FotoForensics. (When over 90% of uploads from a country violate my terms of service, I block the entire country.) However, I've also become much better at stopping porn and fake IDs. I've always known about the correlation between porn and child porn. (Sites that permit porn have a bigger problem with child porn.) However, at least for my services, there is also a correlation between permitting fake IDs and child porn. The drop in reports from 386 to 378 may not appear significant, but FotoForensics received 709,318 unique uploads in 2021 compared to 805,933 in 2022. That's nearly a 15% increase in volume while experiencing a drop in CP sightings. (Woo hoo!)
Keep in mind, all of these bad CyberTip reports and communication issues with NCMEC could be easily resolved by NCMEC. The problem is incentivizing them to be more responsive. As a basic clearinghouse, they only seem to care about the volume of reports and not the content.
Then again, if they really wanted to significantly deter child pornography, they would push to rewrite the laws. Earlier this year, NCMEC's CEO Michelle DeLaune gave testimony to the United States Senate Committee on the Judiciary. Her testimony included recommendations like changing the term from "Child Pornography" (CP) to "Child Sexual Abuse Material" (CSAM). This would extend the scope of what would need to be reported, but would not make it easier for an ESP to find.
Instead, they should consider modifying the laws and NCMEC's processes:
Then again, perhaps NCMEC has outgrown their original purpose. Today, NCMEC helps find missing kids, operates the CyberTipline that receives reports related to online child pornography, operates a massive data storage facility for retaining files, analyzes reports related to missing kids, child porn, and child sex trafficking, manages integrated partnerships with Federal, State, and international law enforcement agencies, provides disaster response activities, coordinates "free or low-cost legal, food, lodging, and transportation services" ( 34 USC 11293 ) for lost or missing children, offers resources for survivors of sexual abuse material , and much more. NCMEC was founded in 1984 and predates the modern internet. It has become a catch-all for any tasks that are related to missing children or potential crimes against children. Maybe NCMEC should be split into more focused entities with clearer separations of duties.
The National Center for Missing and Exploited Children ( NCMEC ) is tasked by Congress to be the national clearinghouse for handling information related to child sexual abuse. NCMEC coordinates with the FBI, US Customs, US Secret Service, US Postal Inspectors, and other law enforcement organizations in order to handle reports from online service providers (Electronic Service Providers, or ESPs).
As someone who provides online services (including FotoForensics , RootAbout , and Hintfo ), the law defines me as an ESP and requires me to be a mandatory reporter for child pornography (CP) on my sites. As noted in 18 U.S. Code § 2258A , if I see child pornography then I must report it to NCMEC's CyberTipline. The reports go from me (and every other ESP) to NCMEC's CyberTipline to any of the Internet Crimes Against Children (ICAC) locations (there's at least one ICAC per state) to local law enforcement. The flow from NCMEC to law enforcement isn't always this lock-step since " FBI personnel assigned to the NCMEC review information that is provided to NCMEC's CyberTipline". (The ESP's CyberTip may go straight to the FBI.)
Since 2019, NCMEC has been releasing a "by the numbers" summary that lists the number of reports per ESP. They just posted the 2022 report last week. Although NCMEC's list is alphabetical, I typically sort it by volume of reports. Here's the top ten ESP reporters for the last few years:
| 2019 | 2020 | 2021 | 2022 | ||||
|---|---|---|---|---|---|---|---|
| 16,836,694 | Total | 21,447,786 | Total | 29,157,083 | Total | 31,802,525 | Total |
| 15,884,511 | 20,307,216 | 22,118,952 | 21,165,208 | ||||
| 449,283 | 546,704 | 3,393,654 | 5,007,902 | Instagram, Inc. | |||
| 123,839 | Microsoft | 144,095 | Snapchat | 1,372,696 | 2,174,548 | ||
| 82,030 | Snapchat | 96,776 | Microsoft | 875,783 | 1,017,555 | WhatsApp Inc. | |
| 74,165 | INHOPE | 65,062 | 512,522 | Snapchat | 608,601 | Omegle.com LLC | |
| 73,929 | Imgur, LLC | 57,170 | INHOPE | 154,618 | TikTok | 551,086 | Snapchat |
| 45,726 | Twitter, Inc. | 31,571 | Imgur | 130,723 | INHOPE | 288,125 | TikTok Inc. |
| 19,480 | Discord Inc. | 22,692 | TikTok | 86,666 | 169,800 | Discord Inc. | |
| 13,418 | Verizon Media | 20,928 | Dropbox | 78,603 | Microsoft | 107,274 | Microsoft - Online Operations |
| 7,360 | Pinterest Inc. | 20,265 | Omegle | 54,742 | Imagebam/Videobam | 98,050 | Twitter, Inc. |
The numbers and names don't match exactly every year. For example, the 2019 "Facebook" was all of Facebook, but 2021 and 2022 separated out Meta's services into Facebook, Instagram, and WhatsApp. (No matter how you slice it, over 90% of reports to NCMEC come from Facebook/Meta.) Similarly, the name "Microsoft" sometimes refers to all of their online properties and sometimes separate properties like "Xbox" and "Online Operations" have their own entries.
Growth in Reporting
Each year, NCMEC receives more CP reports. However, that isn't necessarily because there is more CP. Rather, it's because some ESPs are submitting more reports. For example, Reddit and Discord had significant increases in reporting last year:| Year | Discord | |
|---|---|---|
| 2019 | 724 | 19,480 |
| 2020 | 2,233 | 15,324 |
| 2021 | 10,059 | 29,606 |
| 2022 | 52,592 | 169,800 |
The increase from Reddit suggests that they are being more effective at detecting and reporting it. (I'm sure that the 2021 lawsuit alleging that Reddit was profiting from CP also resulted in changes to their detection and reporting.) Similarly, the change in volume from Discord coincides with a change in their terms of service (compare March 2021 against December 2021 ).
One thing to keep in mind is that every company that hosts other people's uploaded pictures should be a registered ESP. However, the number of registered ESPs at NCMEC really doesn't represent every possible ESP.
| Year | Number of reporting ESPs * |
|---|---|
| 2019 | 148 |
| 2020 | 168 |
| 2021 | 230 |
| 2022 | 236 |
Frankly, there should be a lot more ESPs reporting. The 31 million total reports in 2022 does not come from very many companies. Every single Mastodon service provider should be registered. (I doubt there is zero CP on all of Mastodon.) Every porn site should be registered. Tumblr didn't start reporting until 2021. MailChimp had their first (and only) report in 2022.
Types of ESPs
Over the years I have spoken to people from other registered ESPs. What I've found is that all ESPs really dislike CP. However, they also don't like the reporting process. The reporting issues include not wanting to look at CP, taking too long to report, the overall inconvenience, lack of reporting API libraries (everyone builds their own), and not having enough time for this additional (legally mandatory) work.The amount of cooperation from ESPs varies. In my subjective view, ESPs can be divided into four categories:
ESP #1: Uncooperative
The law says that an ESP must report it if they see it. So some ESPs just don't look. Verizon Wireless only submitted 13 reports over 4 years. (Seriously?!?) AT&T had 2 reports in 2019, 2 in 2020, 1 in 2021, and zero in 2022. And I don't even see T-Mobile listed. And yet, we often hear about child porn associated with high school kids sexting . Sexting means texting, which means Verizon, AT&T, and T-Mobile, among other carriers should be reporting more often. They can't even claim that their access is limited due to encryption since SMS/MMS is unencrypted .Probably the biggest example of an uncooperative company is Apple.
| Year | Reports from Apple Inc |
|---|---|
| 2019 | 205 |
| 2020 | 265 |
| 2021 | 160 |
| 2022 | 234 |
Every year, I report to more CP sightings to NCMEC's CyberTipline than Apple. It isn't that I receive more pictures than Apple or that Apple doesn't receive as much CP. Rather, I think that Apple just doesn't like to report it. Back in 2021, Apple announced a controversial system for automatically detecting CP on user's devices. After much criticism, Apple decided to indefinitely postpone the release. Later, in December 2021, Apple decided to roll out part of their automated detection . As I sarcastically remarked last year , "I certainly expected Apple to submit more than 160 reports to NCMEC." Well, they did, but barely. This certainly isn't the kind of volume I'd expected from an automated detection system.
Rather, Apple seems to be intentionally not reporting. As Apple's SVP Craig Federighi noted in 2021 , Apple uses arbitrary thresholds. Federighi remarked that Apple only looks at the content if their iCloud receives something like 30 flagged files from a user's account. The problem is, 18 USC 2258A says that every ESP has a "Duty To Report" (2258A(a)) and that knowing and willfully failing to report is a felony (2258A(e)). The law doesn't stipulate any thresholds for reporting; if an ESP sees CP then they must report it. For me, some of my reports include multiple pictures, but others only include single sightings. So why can Apple get away with arbitrary thresholds when I have to report everything? That's easy: they have more attorneys.
Then again, there could be another explanation. As I understand it, 18 USC 2252 makes it illegal to intentionally search for CP. This includes searching your own system. Most ESPs have services that forbid general topics, like "no porn". If, while filtering out porn, they encounter CP, then they must report it ( 2258A , mandatory reporting). However, the telecommunication companies (Verizon, AT&T, etc.) don't have any such restrictions, so they can't unintentionally encounter CP while filtering out something else. On the other hand, Apple includes warnings about prohibited content and has mentioned a desire to scan user's content , so I can't see them being able to use this excuse.
ESP #2: Abusively Cooperative
At the other end of the spectrum are the abusively cooperative companies. The basic mentality seems to be to flood NCMEC as punishment for making the ESP do reporting. Forget about accuracy or completeness; just submit as much as possible and let NCMEC sort it out.Personally, I'm guilty of using NCMEC this way. If a picture might be CP, then I submit it because I don't want to spend any time evaluating it. Also, 18 USC 2252 makes it illegal to "knowingly accesses with intent to view", so any detailed evaluation before sending it to the CyberTipline could be illegal. I assume (and hope) that someone at NCMEC, at an ICAC, or in law enforcement will tell me if one of my submissions isn't CP. But in 10 years, that's only happened once.
The best example here is Meta (formerly Facebook; includes Facebook, Instagram, and WhatsApp).
As an ESP, NCMEC does not make it easy to see what my own CyberTips look like. I submit information to the CyberTipline and NCMEC converts it into a report for the ICACs. Unless you've been involved in a legal case, attended NCMEC's annual "Crimes Against Children Conference" (and spoke to the right people there), or did a search online, an ESP will never see one of these reports. Then again, there is a reason for keeping these reports away from the general public: they often contain a lot of personally identifiable information (PII), like names, street addresses, email addresses, IP addresses, and much more. (But this doesn't explain why an ESP can't see their own reports.)2019: NCMEC received 16 million reports, 15 million from Facebook
2020: NCMEC received 21 million reports, 20 million from Facebook
2021: NCMEC received 29 million reports, 26 million from Meta
2022: NCMEC received 31 million reports, 27 million from Meta
Over the years, I have repeatedly asked NCMEC for a copy of one of my reports -- just to see what the data going in looks like when it comes out. NCMEC runs a test server for ESPs to develop their submission methods (never upload real CP to the test server), but I can't even get a copy of a report from that. I've had NCMEC employees tell me that they can generate a test report for me from the test server, but when I run the test submission, they never respond to the request for the test report. (This has been going on for years.)
Having said that, I've seen a few dozen CyberTipline reports generated by NCMEC, including one of my own. (NCMEC never provided them directly to me and I wasn't allowed to keep a copy of my own report.) These have included reports from Google ( example 1 , example 2 ), Facebook, and a handful of other ESPs. Google's reports don't usually have obvious errors. However in my experience, every single report from Meta (and Facebook before that) has been filled out wrong . Some of the errors are really basic (like the failing to read NCMEC's documentation and providing the wrong data), while others misrepresent information. (I can't tell if it's malicious or incompetence, so let's assume the latter.) In any case, Meta accounts for over 90% of submissions to NCMEC (87% in 2022), so over 90% of those CyberTips to NCMEC are effectively junk. (If you're law enforcement and working with a Meta CyberTipline report, just assume that the chain of custody is broken.)
Keep in mind, NCMEC doesn't validate the information from the ESPs. They just receive it, correlate and combine it with other reports, and forward it to law enforcement (FBI, ICAC, etc.). NCMEC is a clearinghouse and not a validation center. The assumption is that law enforcement will see any errors or incomplete information and decide how to handle the data. However, that's never what happens. In my experience, if law enforcement can misinterpret the data, then they will misinterpret it.
Also, the high volume of junk submissions from Meta doesn't hurt NCMEC. If anything, it helps them justify to Congress and the Department of Justice why NCMEC needs additional funding each year.
ESP #3: Basic Cooperative
The majority of ESPs (not the majority of reports) are basically cooperative. They fill out the complex submission form as best they can. They include the mandatory information (reporter's name, date, time, and incident type) and some of the optional information (copy of the media, IP addresses, etc.). Some ESPs try to protect personal information, so names and logs may require a warrant.I did mention that Meta has errors in their reports. Unfortunately, that is sometimes the case for reports from other ESPs. However, the quantity and quality of errors are rarely as bad as Meta. (If NCMEC provided sample reports back to the ESPs for validating their submission process, then most of these errors could be corrected pretty quickly.)
ESP #4: Aggressively Cooperative
This is me and a handful of other ESPs. I don't like CP, but I also don't like extra work. When someone uploads CP to my site, I'm very likely to notice it. At that point, I have a choice: I can either report them or take a felony for not reporting them. In this case, they will lose every time because I will report them. Moreover, because they forced me to do work and to accept some degree of liability ( 2258B provides protection from liability in exchange for reporting), I'm going to turn over everything I know about them. And as the person who owns the server, I know a lot about the offending users.Having said that, every year I try to improve my detection and reporting process. I've learned that the faster I detect and block the offenders, the fewer offenders I receive. As a result, I've seen a drop in the number of CP reports that I've needed to submit to the CyberTipline:
| Year | Reports from Hacker Factor |
|---|---|
| 2019 | 608 |
| 2020 | 523 |
| 2021 | 386 |
| 2022 | 378 |
My big drop from 2020 to 2021 was because I cut off all of Russia from using FotoForensics. (When over 90% of uploads from a country violate my terms of service, I block the entire country.) However, I've also become much better at stopping porn and fake IDs. I've always known about the correlation between porn and child porn. (Sites that permit porn have a bigger problem with child porn.) However, at least for my services, there is also a correlation between permitting fake IDs and child porn. The drop in reports from 386 to 378 may not appear significant, but FotoForensics received 709,318 unique uploads in 2021 compared to 805,933 in 2022. That's nearly a 15% increase in volume while experiencing a drop in CP sightings. (Woo hoo!)
Proposed Changes
When I first started interacting with NCMEC (in 2013), I found their organization to be very easy to work with. They even started incorporating some of my forensic tools into their analysis process. However, they have had a couple of big management changes. Each time this happens, they become less and less responsive. For example, I used to be able to email them with updates for my previous CyberTip reports and they would attach the update to the report. This year, I was told that they can no longer apply updates. I can only provide an update by submitting a new report (or wait for a warrant that requests any additional information). On rare occasions I send emails to them that ask for clarification or assistance. Circa 2013, they would respond within a day. Over the last year? Usually they don't respond, and if they respond, it's weeks later.Keep in mind, all of these bad CyberTip reports and communication issues with NCMEC could be easily resolved by NCMEC. The problem is incentivizing them to be more responsive. As a basic clearinghouse, they only seem to care about the volume of reports and not the content.
Then again, if they really wanted to significantly deter child pornography, they would push to rewrite the laws. Earlier this year, NCMEC's CEO Michelle DeLaune gave testimony to the United States Senate Committee on the Judiciary. Her testimony included recommendations like changing the term from "Child Pornography" (CP) to "Child Sexual Abuse Material" (CSAM). This would extend the scope of what would need to be reported, but would not make it easier for an ESP to find.
Instead, they should consider modifying the laws and NCMEC's processes:
Then again, perhaps NCMEC has outgrown their original purpose. Today, NCMEC helps find missing kids, operates the CyberTipline that receives reports related to online child pornography, operates a massive data storage facility for retaining files, analyzes reports related to missing kids, child porn, and child sex trafficking, manages integrated partnerships with Federal, State, and international law enforcement agencies, provides disaster response activities, coordinates "free or low-cost legal, food, lodging, and transportation services" ( 34 USC 11293 ) for lost or missing children, offers resources for survivors of sexual abuse material , and much more. NCMEC was founded in 1984 and predates the modern internet. It has become a catch-all for any tasks that are related to missing children or potential crimes against children. Maybe NCMEC should be split into more focused entities with clearer separations of duties.
Značky: #Forensics, #Network, #FotoForensics