-
At
chevron_right
Le droit, la justice et internet.
motius · pubsub.gugod.fr / atomtest · Saturday, 19 September, 2015 - 22:00 · 12 minutes
Bonjour à tous ! L'épée contre le bouclier symbolise un éternel équilibre dans une guerre, mais à la fin, qui gagne ? Aujourd'hui je vous propose d'aller jeter un coup d'œil du côté d'un de nos outils favoris : l'internet, ses monts et merveilles, et le reste... La plupart d'entre vous êtes familier...
Bonjour à tous !
L'épée contre le bouclier symbolise un éternel équilibre dans une guerre, mais à la fin, qui gagne ? Aujourd'hui je vous propose d'aller jeter un coup d'œil du côté d'un de nos outils favoris : l'internet, ses monts et merveilles, et le reste...
La plupart d'entre vous êtes familiers des concepts que je vais décrire dans cette première partie, mais elle me semble essentielle afin que l'on parte d'une base commune.
Quelques définitions...
Je vais essayer d'être suffisamment clair pour qu'il vous soit inutile de suivre les liens indiqués dans l'article, cependant je les inclus à toutes fins utiles.
Internet : Il s'agit d'un réseau physique reliant des machines. En gros des tuyaux transportant de l'information, normalement sans en modifier le contenu (donnée). Schématiquement, il n'existe que deux objets sur internet :
- des ordinateurs ;
- des "câbles" (fibre optique, réseau cuivre, antennes 3G, 4G, ...).
Internet est en fait un réseau de réseaux : chaque opérateur internet (FAI) construit son bout de réseau, qu'il interconnecte ensuite aux autres (il y a pas mal de questions de taille d'opérateur, de gros sous, d'organisation des réseaux, mais on va faire simple). L'étymologie du mot internet décrit cela : il s'agit d'une interconnexion (inter) de réseaux (network).
Cela dit, dans tout cet article, une représentation schématique à peu près équivalente d'internet sera utilisée (vous pouvez cliquer pour afficher les images taille réelle dans un nouvel onglet) :
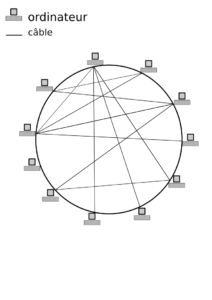
Représentation d'un réseau physique de machines. Schéma simplifié d'internet. CC-BY-SA
Web : réseau virtuel de machines. Ce réseau utilise l'infrastructure qu'est l'internet. Il est constitué de deux types d'objets :
- les machines client-web. Celles-ci peuvent demander du contenu (via le protocole HTTP) ;
- les machines serveur-web. Celles-ci proposent du contenu.
Il est tout à fait possible pour une machine d'être à la fois client-web et serveur-web. Le web peut être vu comme une sous-partie d'internet, tous les ordinateurs connectés pouvant théoriquement proposer et demander du contenu. Le web est un réseau virtuel.
Protocole : manière qu'ont plusieurs ordinateurs de communiquer. HTTP est un protocole du Web. De manière non-exhaustive, les protocoles incluent HTTP/HTTPS, FTP, BitTorrent, SSH...
Serveur : une machine qui propose du contenu ou service. Exemples, un serveur web propose des pages web (via le protocole HTTP/HTTPS), alors qu'un serveur proxy effectue des requêtes à votre place de telle sorte qu'il semble que c'est lui et non pas vous qui a effectué la recherche.
Client : une machine qui demande du contenu ou service. La majorité des internautes ne sont que clients.
Donnée : de l'information. (Volontairement court : une méta-donnée est de la donnée, et peut très bien être considérée comme de la donnée pure, selon le contexte).
Méta-donnée : de l'information à propos d'une information ou personne, objet... Exemple : les métadonnées d'une image sont :
- la date ;
- l'heure ;
- le type d'appareil photo ;
- la géolocalisation (éventuellement).
Ce concept est complexe. En effet si une image passe sur internet, les métadonnées des paquets IP sont les adresses IP source et destination (etc.), et les métadonnées de la photo sont des données sur internet.
Chiffrement : Le fait de transformer une donnée numérique à l'aide d'algorithmes mathématiques afin de la rendre indéchiffrable pour quiconque en dehors de la personne à qui la donnée est destinée.
Déchiffrement : le fait d'obtenir les données en clair à partir du flux chiffré.
Décryptage : opération qui consiste à essayer de casser le chiffrement protégeant de la donnée.
Empreinte (hash) : suite de caractère identifiant de manière unique de la donnée à l'aide d'un algorithme. Les algorithmes utilisés actuellement sont : MD5 (vraiment obsolète, et déconseillé), SHA-1 (en voie d'obsolescence depuis 2015, le plus utilisé), SHA-2 (assez peu utilisé), ou SHA-3 (usage vraiment marginal).
Signature : le fait d'authentifier les données. Cette opération se fait en deux temps : le serveur réalise une empreinte des données, puis il signe l'empreinte. Vérifier l'intégrité des données consiste à effectuer l'empreinte et vérifier la signature.
Comment les mathématiques contournent le droit.
Comme d'habitude, je vais essayer de présenter les faits le plus objectivement possible (ce qui sera assez facile, étant donné qu'il s'agit d'abord d'un sujet technique) puis émettre une opinion - bien personnelle, comme toujours - que je vous encourage à critiquer dans les commentaires.
Le fil de cet article sera le suivant :
- tout d'abord, je vais présenter les principes du réseau d'anonymisation (ici tor que la majorité d'entre vous connaît) ;
- puis les principes mathématiques des techniques de chiffrement puissant de nos communications (PFS, OTR, GPG/OpenPGP/PGP...) ;
- et enfin les principes mathématiques pour rendre improuvable l'existence d'une donnée (utilisés par TrueCrypt, CypherShed, VeraCrypt).
(En fait l'idée de nouvelles possibilités à l'aide des mathématiques n'est pas nouvelle : le principe du VPN ou du chiffrement permet de s'abstraire du risque d'un réseau non sécurisé en soi...)
Du réseau d'anonymisation
Un petit schéma aidera à mettre les idées au clair, mais pas si vite ! Rien ne vaut un petit parallèle avec ce que vous connaissez déjà...
Lorsque vous chargez une page web en HTTP (flux non-chiffré, non-signé) il se passe ça :
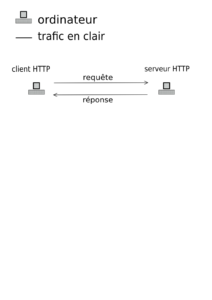
Trafic HTTP (Web). Requête, réponse. CC-BY-SA.
La suite d’événement est :
- le client parle au serveur (connexion) ;
- le serveur dit "je parle HTTP" ;
- le client demande la page web identifiée de manière unique par une URL ;
- le serveur répond :
- "200 OK", s'il l'a, puis la transmet ;
- "404 Error", s'il ne l'a pas (la très fameuse "Erreur 404" que tout le monde connaît, et facile à obtenir, il suffit de demander une page qui n'existe pas à un serveur).
De même, demander une page web en HTTPS, ça se représente comme ça :
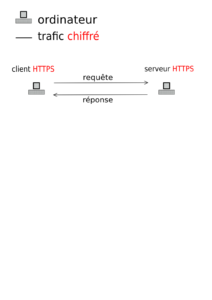
Trafic HTTPS (Web). Requête, réponse. CC-BY-SA.
La suite d’événement est presque identique :
- le client parle au serveur (connexion) ;
- le serveur dit "Je parle HTTPS" ;
- le client demande en HTTPS l'URL ;
- le serveur répond :
- "200 OK", s'il l'a, puis l'envoie
- "404 Error", sinon.
Deux différence entre HTTP et HTTPS, avec HTTPS :
- le trafic est chiffré (impossible de lire) ;
- le trafic est signé (impossible d'altérer le contenu, s'il était modifié, le client jetterait les paquets IP et les redemanderait).
Eh bien utiliser tor, ça ressemble à ça (décrit ici par le projet tor) :
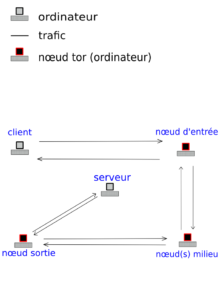
Trafic tor. CC-BY-SA.
C'est-à-dire que tor fonctionne comme s'il y avait au minimum (parce qu'il peut y avoir plusieurs nœuds milieu en théorie) trois proxy (ou intermédiaires) entre nous et le serveur que l'on interroge.
Tor est ainsi un réseau virtuel de machines serveur appelées "nœud". Il y a trois type de nœuds :
- entrant ;
- milieu ;
- sortant.
Le trafic ressemble donc à ceci :
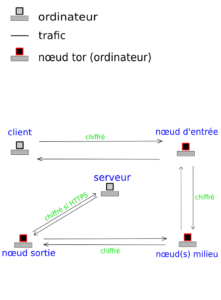
Apparence du trafic avec tor. CC-BY-SA.
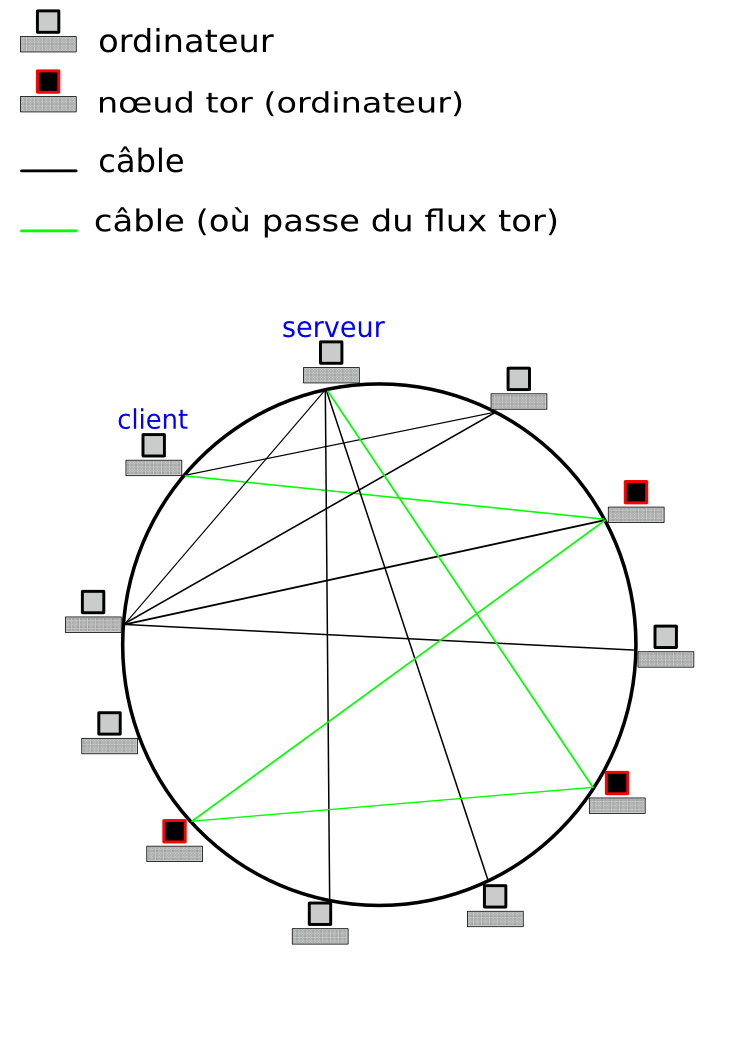
Une représentation complète de l'internet avec du trafic tor serait :
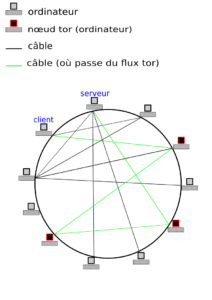 ](https://hashtagueule.fr/assets/2015/09/tor.png)
](https://hashtagueule.fr/assets/2015/09/tor.png)
{kind=link}
Trafic tor sur internet. CC-BY-SA.
Utiliser le réseau tor permet donc un anonymat de très grande qualité, en effet :
- le FAI qui relie l'abonné ne voit que du trafic, qu'il peut identifier comme étant du trafic tor, même en HTTP ;
- le serveur ne sait pas qui a demandé sa page ou son service ;
- le nœud d'entrée ne connait que l'utilisateur, pas le contenu (même en HTTP) ;
- le relais milieu ne connaît que ses voisins (ou les relais milieu...) ;
- le nœud sortie connaît le nœud milieu et le serveur interrogé, et voit :
- soit du trafic HTTPS indéchiffrable ;
- soit le trafic HTTP demandé, en clair.
Ainsi l'utilisation de tor, par le grand anonymat qu'il permet, empêche de relier un utilisateur au trafic qu'il a demandé.
L'utilisation de tor fait donc disparaître les informations liées à une connection : les métadonnées.
Une communication irrémédiablement chiffrée
Une communication chiffrée, une clef de chiffrement. Une idée gargantuesque consiste à enregistrer, au niveau d'un État, tout le trafic chiffré qui passe, et de l'analyser après, avec plusieurs idées derrière la tête :
- on trouvera peut-être des failles dans les protocoles de chiffrement actuels ;
- les utilisateurs perdront/divulgueront peut-être leur clef ;
- dans le cas d'une enquête légale, on demandera les clefs de chiffrement.
Eh bien les beaux jours des clefs perdues sont terminés (ou presque). En effet, dans un échange de clefs de type Diffie-Hellman :
- même si l'on perd les clefs ayant servit à un échange chiffré ;
- même si tout le trafic chiffré a été enregistré,
la conversation ne sera pas déchiffrable. Expliquons le procédé.
Il s'agit d'un échange de clefs de chiffrement au travers d'un réseau non sécurisé (internet) sans divulgation d'information. Pour le décrire, je vais procéder comme Wikipédia, à l'aide de couleurs :
- Alice possède une couleur secrète A, et tire au hasard une couleur A' ;
- Bob possède une couleur secrète B, et tire au hasard une couleur secrète B',
puis :
- Alice mélange A et A', qui donne A
''; - Bob mélange B et B' qui donne B
'',
puis
- Alice envoie A
''sur le réseau ; - Bob envoie B
''sur le réseau,
ces couleurs peuvent être "entendues" (par un tiers espionnant) sur le réseau, si le réseau est enregistré, puis :
- Alice mélange B
''avec A'', et obtient C = (A + A' + B + B') - Bob mélange A
''avec B'', et obtient (A + A' + B + B') = C !
Ainsi :
- Alice et Bob ont réussi à créer un couleur C inconnue pour le réseau ;
- De plus, cette couleur est temporaire : Alice et Bob ont tiré pour cette communication A' et B' ;
- En enfin, cerise sur le gâteau, on ne peut pas déchiffrer la conversation sans avoir à la fois A' et B', qui sont supprimées par Alice et Bob, puisqu'il s'agit de clefs temporaires. Même si l'on obtenais B' de Bob, il manquerait toujours A'.
En conclusion, Alice et Bob ont un moyen de communiquer qui empêche le déchiffrement a posteriori. Au niveau du réseau, la reconstitution de l'échange est devenue impossible.
Cette fonctionnalité s'appelle PFS (Perfect Forward Secrecy : confidentialité persistante) pour le web, OTR (Off-The-Record Messaging : messagerie confidentielle) pour la messagerie instantanée (utilisant par exemple le protocole XMPP).
Ici, ce sont les données de la conversation qui disparaissent.
Information, existes-tu ?
Un autre recours de l'enquête est la perquisition : physiquement aller voir l'information. Dernière déception pour les tenants du contrôle, ça n'est plus possible. Un mécanisme appelé "déni-plausible" consiste à pouvoir cacher si bien une donnée qu'il devient impossible de faire la preuve de son existence. Plongée dans les profondeurs du mystère...
Ces technologies sont très fortement associées à des logiciels, et à une actualité liée (probablement) à la NSA, mais à hashtagueule on a prévu de rester, donc on va faire court, quitte à revenir là-dessus sur une prochaine news. Je parlerai indifféremment de TrueCrypt (et ses descendants VeraCrypt, CypherShed, et j'en passe) comme synonyme du déni-plausible pour la clarté de l'article, mais ces logiciels permettent bien plus.
Rien ne vaut un exemple : TrueCrypt permet de créer des volumes chiffrés, ainsi :
- Ève crée un volume A de 100 Go de données personnelles, chiffré avec une clef α ;
- elle crée un sous-volume E de 100 Mo de données très confidentielles, chiffrées avec une clef ε.
Si quelqu'un accède à cet ordinateur, il verra le volume A chiffré, et ne pourra pas accéder aux données. Si ce quelqu'un est la justice, elle peut l'obliger légalement (même article que plus haut) à lui donner accès à ses clefs de chiffrement. Il lui suffit de ne donner que la clef α à la justice, et elle ne verra que le volume A de 100 Go (moins 100 Mo). Le sous-volume chiffré sera toujours inaccessible, et qui plus est, il ressemblera toujours à des données aléatoires, comme avant le déchiffrement de A. (Les données de E ne sont pas protégées contre la destruction, mais c'est une autre affaire).
Ainsi, l'existence de données dans E n'est pas prouvable, et il est même plausible qu'il n'y ai rien à cet endroit. C'est comme cela que l'on peut cacher des données.
En conclusion
Vous m'avez probablement vu arriver avec mes gros sabots, mais je vais quand même récapituler :
- on peut stocker une information sans qu'elle ne soit jamais accessible que par son propriétaire (3ème paragraphe) ;
- il est possible pour deux personnes de communiquer sans que leur trafic ne soit jamais déchiffrable (décryptable, c'est une autre affaire) (2ème paragraphe) ;
- il est possible pour deux ordinateurs de communiquer sans qu'aucun acteur du réseau ne le sache (1er paragraphe).
La totalité de la conversation a donc disparu des radars : les métadonnées de la conversation, le contenu de la conversation, et la copie locale sauvegardée.
Tout ceci est possible, là, maintenant, avec des logiciels open-source (ou libres) dont le code source (c'est-à-dire l'application logicielle de la formule mathématique, avant d'être traduite en langage ordinateur) est disponible au téléchargement (vous utilisez peut-être de la PFS avec hashtagueule.fr sans le savoir).
La conclusion (personnelle, vous le rappelez-vous ?), c’est qu’on ne peut gagner le volet numérique de la guerre contre le terrorisme par les seules voies législatives ("When you have a hammer, everything looks like a nail" ;-) ).
{kind=link}
Encore un dernier exemple (fictif celui-là) pour illustrer le pire des cas : un groupe terroriste qui est la tête-pensante, cherchant à radicaliser des jeunes, en vue d'en faire des terroristes. Son outil numérique ultime consiste à faire une solution logicielle reprenant les trois concepts, de faire le tout de manière décentralisée, et d'automatiser le processus de distribution.
Les derniers points que j'ai survolé :
- le côté open-source donne l'assurance du code qui est exécuté ;
- le côté décentralisé délivre de la nécessité d'un tiers (pour les mails, le chat...)
La vraie conclusion est qu'il ne faut pas faire de bêtises en matière de numérique, parce que tout ce que j'ai écrit n'est qu'une compilation d'informations publiquement disponibles sur internet, et maintes fois redondées.
N'hésitez pas à commenter et donner votre avis dans la section commentaires !
Motius