-
At
chevron_right
Let's Encrypt sur HAProxy (Partie 2)
raspbeguy · pubsub.gugod.fr / atomtest · Friday, 10 November, 2017 - 23:00 · 8 minutes
Le fonctionnement de la Terre, avant qu'un certain Galilée y mette son grain de sel, a toujours déchaîné les passions des Hommes et a consommé beaucoup d'encre. Parmi les théories les plus folles, Terry Pratchett nous enseigne dans sa série de livres du Disque Monde que le monde repose sur le dos de...
Le fonctionnement de la Terre, avant qu'un certain Galilée y mette son grain de sel, a toujours déchaîné les passions des Hommes et a consommé beaucoup d'encre. Parmi les théories les plus folles, Terry Pratchett nous enseigne dans sa série de livres du Disque Monde que le monde repose sur le dos de quatre gigantesques éléphants, eux-même reposant sur la carapace d'une tortue encore plus gigantesque appelée A'Tuin. Les quatre éléphants (Bérilia, Tubul, Ti-Phon l'Immense et Jérakine) se répartissent la charge que représente le poids du disque terrestre grâce à la rotation quotidienne de ce dernier. Si maintenant vous ne voyez pas le rapport entre une cosmologie impliquant des animaux au moins aussi grands que des continents capable de tenir en apnée pendant des milliards d'années et le sujet d'aujourd'hui, alors je ne sais plus quoi faire.
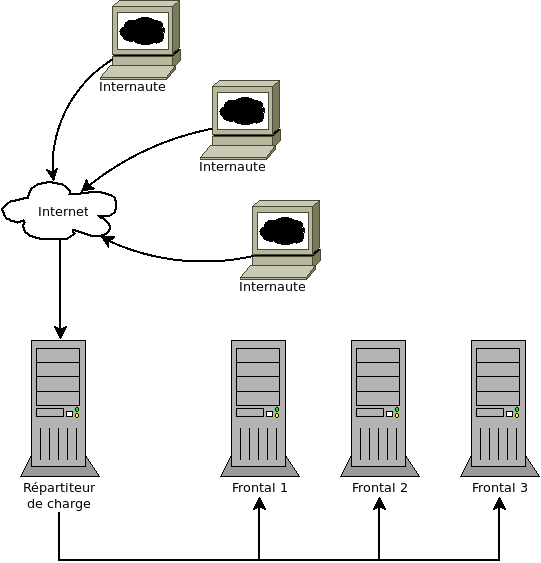
Nous avons vu il y a quelques jours les principes de base d'un répartiteur de charge et exposé brièvement les concepts fondamentaux de HAProxy. Nous avons également mené une réflexion sur la manière de gérer un certificat sur une architecture avec répartiteur de charge et la voix du bon sens nous a susurré que le certificat devait être porté par HAProxy. Bon, mettons ça en pratique.
Rangez vos affaires, sortez une feuille, interro surprise. Rappelez-moi ce qu'est le principe de base du protocole ACME. Et comme vous suivez bien et que vous buvez les paroles de l'instituteur comme un breton boit du cidre, vous saurez donc me répondre que l'agent de certification crée un challenge ACME en générant des fichiers de test auxquels le serveur ACME devra pouvoir accéder via HTTP, ces fichiers étant soit servis par l'agent via un serveur web intégré, soit mis à disposition du serveur de notre choix qui servira ces fichiers en statique. C'est en pratique presque toujours la deuxième solution qui est utilisée, sachant que justement, un serveur web tourne déjà sur les ports web standard (80 et 443). On ne veut pas d'interruption de service, non mais.
Serveur statique
Nous avons un petit problème ici. Les ports HTTP sont utilisés par HAProxy, qui n'est pas un serveur web, mais un répartiteur de charge. Souvenez-vous, il ne peut pas générer de lui même un flux web, pas même servir des fichiers statiques, il se contente de relayer des flux web créés par d'autres serveurs. Conclusion : il nous faut un serveur web tournant sur la machine hébergeant HAProxy capable de servir des fichiers statiques. L'idée, c'est qu'on va faire écouter ce serveur uniquement en local, et HAProxy se chargera de le propulser sur le réseau publique.
On n'a que l'embarras du choix pour trouver un serveur web sachant servir du bon vieux statique. On pourrait choisir Nginx ou Lighttpd par exemple, mais comme nous sommes sur OpenBSD, le choix se portera sur le serveur web déjà préinstallé, communément appelé openhttpd.
Première étape, il faut dire à OpenBSD d'activer le service.
echo 'httpd_flags=""' >> /etc/rc.conf.localAinsi on pourra démarrer le service, et il sera démarré à chaque démarrage de l'OS.
Ensuite, il va nous falloir créer un dossier qui va accueillir les fichiers du challenge ACME. Comme le processus httpd est chrooté dans /var/www (sur OpenBSD, on appelle ça un jail), ce dossier sera donc /var/www/htdocs/webroot.
La configuration de notre httpd sera on ne peut plus simple :
server "default" {
listen on 127.0.0.1 port 1375 #ça fait "let's" en l33t
root "/htdocs/webroot"
}Démarrons le service :
/etc/rc.d/httpd startNotre serveur statique est prêt.
Configuration HAProxy
Il faut dire à HAProxy de rediriger les requêtes ACME vers notre serveur statique fraîchement configuré.
Pour ça, on va définir un backend dédié à Let's Encrypt, vers lequel seront redirigés tous les flux ACME reçus sur les frontends qui nous intéressent.
backend letsencrypt-backend
server letsencrypt 127.0.0.1:1375Propre. Syntaxe explicite, pas besoin d'expliquer je pense. Je fais juste remarquer qu'en plus de nommer le backend globalement, je donne un nom au serveur du backend même si ici il n'a aucune forme d'importance, il ne sera jamais appelé ailleurs dans le fichier, c'est néanmoins obligatoire sur HAProxy. Enfin, un nom clair est toujours profitable, car il est éventuellement utilisé dans ses logs, ses statistiques et il rend la lecture du fichier de conf plus facile.
Le backend est prêt, c'est excellent, mais encore faut-il l'utiliser. Pour être exact, on ne va l'utiliser que si l'URL demandée correspond au chemin classique demandé par le validateur ACME, à savoir /.well-known/acme-challenge/. Reprenons l'exemple de la dernière fois, modifions-le de la sorte :
frontend mon_super_site
bind *:80
mode http
acl url-back-office path_dir /admin
acl letsencrypt-acl path_beg /.well-known/acme-challenge/
use_backend back-office if url-back-office
use_backend letsencrypt-backend if letsencrypt-acl
default_backend mes-frontaux
backend back-office
server backoffice 192.168.0.14:80
backend mes-frontaux
balance roundrobin
server backoffice1 192.168.0.11:80
server backoffice2 192.168.0.12:80
server backoffice3 192.168.0.13:80
backend letsencrypt-backend
server letsencrypt 127.0.0.1:1375On a ajouté une ACL et une directive use_backend. Rappelez-vous, une ACL est tout simplement une condition, ici elle porte sur le chemin de l'URL. Rien de nouveau, on a déjà expliqué le concept.
On recharge le schmilblick :
/etc/rc.d/haproxy reloadOn est prêt à générer notre premier certificat. Mais on ne va pas le faire tout de suite. Comme vous vous en souvenez, HAProxy veut ses certificats sous une forme un peu spécifique, il nous faut donc traiter le certificat dès qu'il a été généré, et pour ça on va faire un peu de scripting. On pourrait déjà générer le certificat sans le script de post-traitement, mais si on faisait ça, on devrait ensuite éditer la configuration d'acme.sh et c'est un peu barbant, sachant que la commande qui génère le premier certificat génère également par magie la configuration associée pour les renouvellements. Donc ce serait stupide.
Script de post traitement
Rien de bien compliqué, je vous rassure. Le principe est simple : HAProxy n’accepte des certificats que sous la forme d'un fichier contenant la chaîne complète de certification et la clef privée, dans cet ordre.
Le script est très simple. Vous pouvez bien entendu le mettre où bon bous semble, pour ma part j'ai décidé de le mettre dans /etc/haproxy/generate-ssl.sh.
#!/bin/sh
SITE=$1
LE_CERT_LOCATION=/root/.acme.sh/$SITE
HA_CERT_LOCATION=/etc/haproxy/ssl
cat $LE_CERT_LOCATION/fullchain.cer $LE_CERT_LOCATION/$SITE.key > $HA_CERT_LOCATION/$SITE.haproxy.pem
/etc/rc.d/haproxy reloadLE_CERT_LOCATION représente l'endroit où seront générés les certificats par acme.sh (il s'agit ici de l'emplacement par défaut, mais vous pouvez changer ce chemin à condition d'utiliser l'option adéquate lors de la génération du premier certificat).
HA_CERT_LOCATION est l'emplacement où seront créés les certificats au format HAProxy. D'ailleurs, n'oubliez pas de créer le dossier en question.
Le script devra être appelé avec en paramètre le domaine complet principal du certificat. N'oubliez pas de le rendre exécutable.
Génération du premier certificat
On y est, maintenant on va enfin pouvoir générer ce satané certificat. Partons du principe que vous avez correctement installé acme.sh, le README du projet est très simple à suivre.
acme.sh --issue -d mon-super-site.com -w /var/www/htdocs/webroot/ --renew-hook "/etc/haproxy/generate-ssl.sh mon-super-site.com" --debug
Remarquez que vous pouvez générer un certificat couvrant plusieurs domaines à la fois, il suffit d'ajouter -d mon-domaine-secondaire.com entre le domaine principal et l'option -w. Remarquez l'option --renew-hook, elle permet d'appeler le script qu'on vient de définir à chaque fois qu'un renouvellement est effectué.
Une fois la commande effectuée avec succès (ça peut prendre une minute ou deux), votre certificat est généré, il vous faut encore ajouter le certificat dans la configuration du frontend comme il suit :
bind *:443 ssl cert /etc/haproxy/ssl/mon-super-site.com.haproxy.pemComme il s'agit de la première génération et non d'un renouvellement, il est nécessaire d'appliquer le script à la main.
/etc/haproxy/generate-ssl.sh mon-super-site.comVérifiez, et pleurez de joie. Votre certificat est déployé et fonctionnel. C'est magnifique.
Automatisation du renouvellement
Ultime étape, celle qui fait prendre tout son sens à la révolution Let's Encrypt, celle qui fait qu'on peut oublier sans scrupule que tel ou tel site a un certificat proche de l'expiration, il s'agit du renouvellement automatique. Pas de subtilités, une simple ligne dans la crontab fait l'affaire. Et en plus, si je ne dis pas de bêtises, acme.sh s'occupe tout seul d'ajouter cette ligne.
26 0 * * * "/root/.acme.sh"/acme.sh --cron --home "/root/.acme.sh" > /dev/nullLa commande sera lancée tous les jours à minuit vingt-six, libre à vous de changer cet horaire. acme.sh sera assez intelligent pour savoir si votre certificat a besoin d'un coup de jeune ou non, donc rassurez vous, il n'y aura pas un renouvellement par jour.
Conclusion
Le protocole ACME peut s'appliquer à toutes les architectures web pour peu qu'on puisse traiter les requêtes du challenge correctement. À moins de disposer d'un stockage partagé (NSF, iSCSI, Samba...), il est indispensable que le challenge ACME soit créé par la machine capable de le traiter.
Illustration : The Great A'Tuin par Paul Kidby