-
 chevron_right
chevron_right
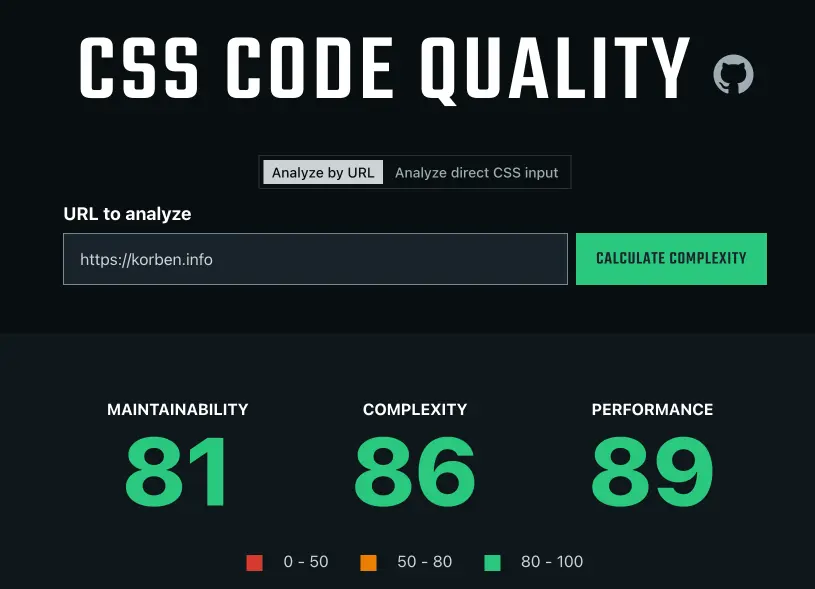
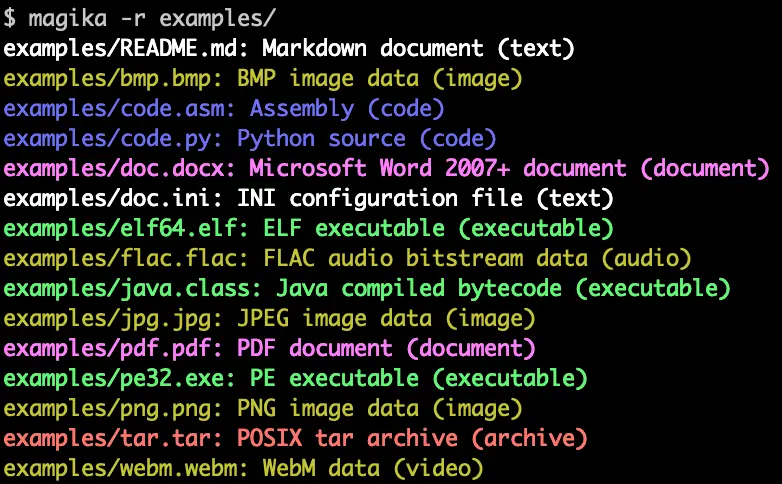
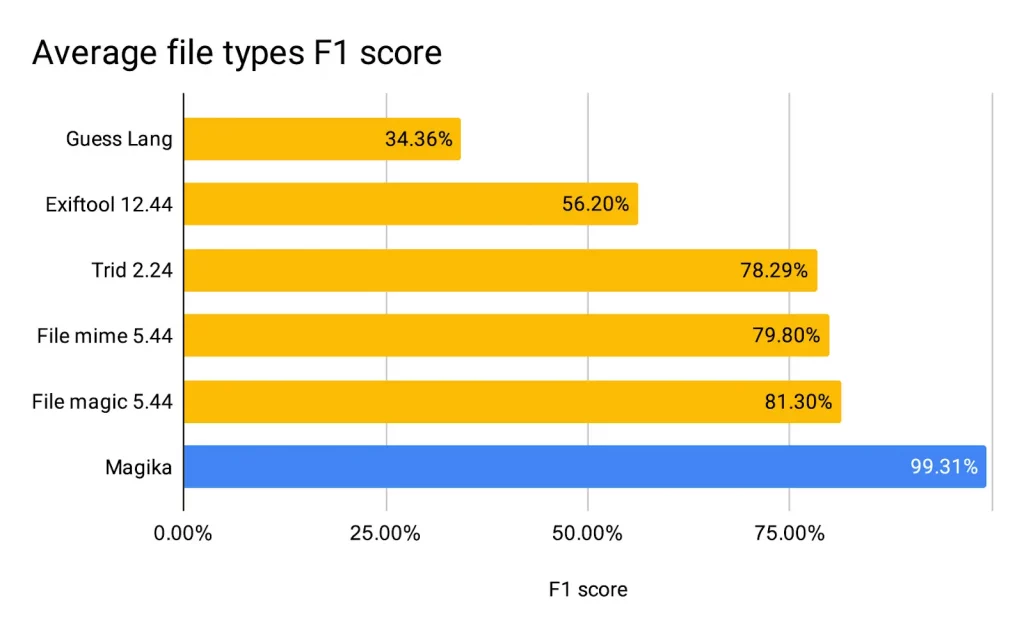
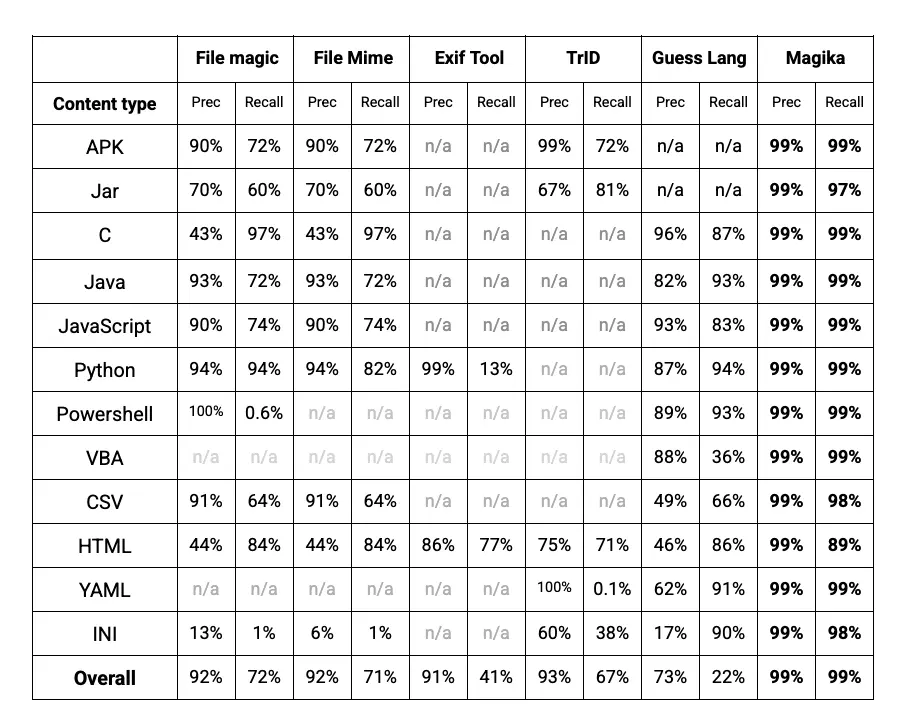
Sprite Fusion – Un éditeur de niveaux 2D pour vos jeux, utilisable directement dans le navigateur
news.movim.eu / Korben · Thursday, 21 March - 08:00 · 2 minutes

![]()
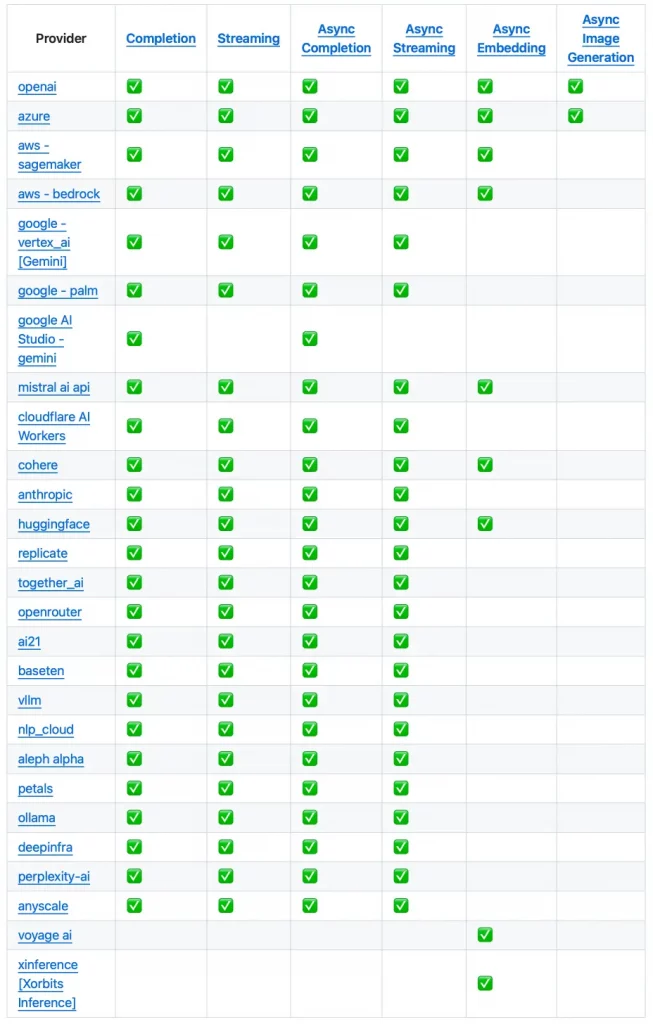
Mes amis, laissez-moi aujourd’hui vous parler de Sprite Fusion , un outil gratuit de conception de niveaux 2D qui vous permet de créer de magnifiques cartes de tuiles (les fameuses « tiles ») directement dans votre navigateur.
Grâce à cet éditeur vous allez pouvoir concevoir rapidement des niveaux pour vos propres jeux.
Pour commencer, il est très facile de charger vos ensembles de tuiles avec un simple glisser-déposer ou un copier-coller. Ensuite, avec l’éditeur de cartes de tuiles, vous pouvez créer vos niveaux en utilisant des sélections de tuiles uniques ou multiples.
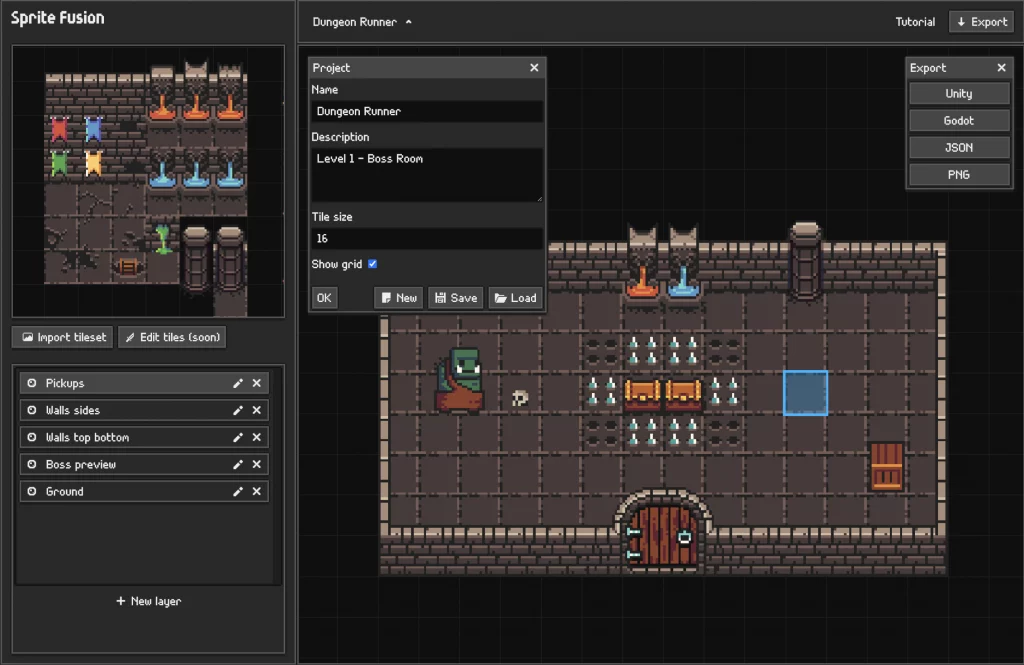
Alors, qu’est-ce qu’une carte de tuiles, exactement ?
Et bien c’est une carte 2D composée de petites images répétées pour créer une carte. Les cartes de tuiles sont utilisées dans de nombreux types de jeux, comme des jeux de plateforme ou encore des RPG.
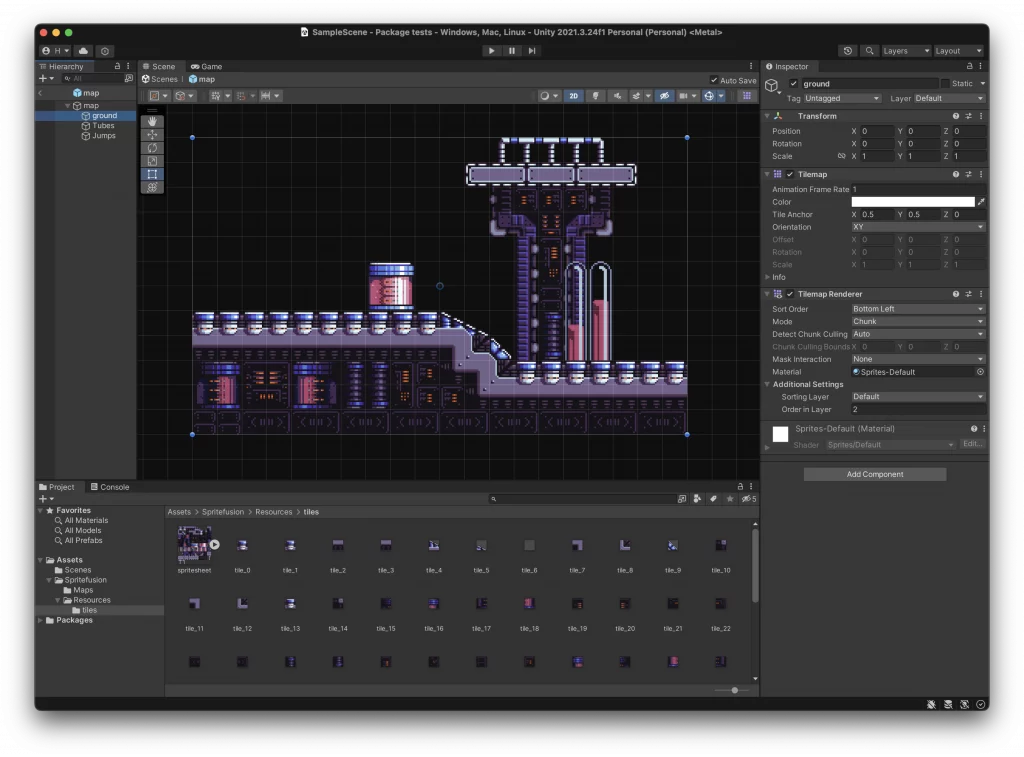
Avec Sprite Fusion, il est possible d’exporter directement votre carte en tant que Tilemap Unity native ou en tant que scène TileMap Godot. De plus, Sprite Fusion inclut un système automatique de tuiles facile à utiliser dès le départ pour une conception rapide du terrain. Vous n’avez pas besoin de code personnalisé, il vous suffit d’exporter votre carte de tuiles en tant que package Unity ou scène Godot et de la faire glisser et déposer dans votre moteur !
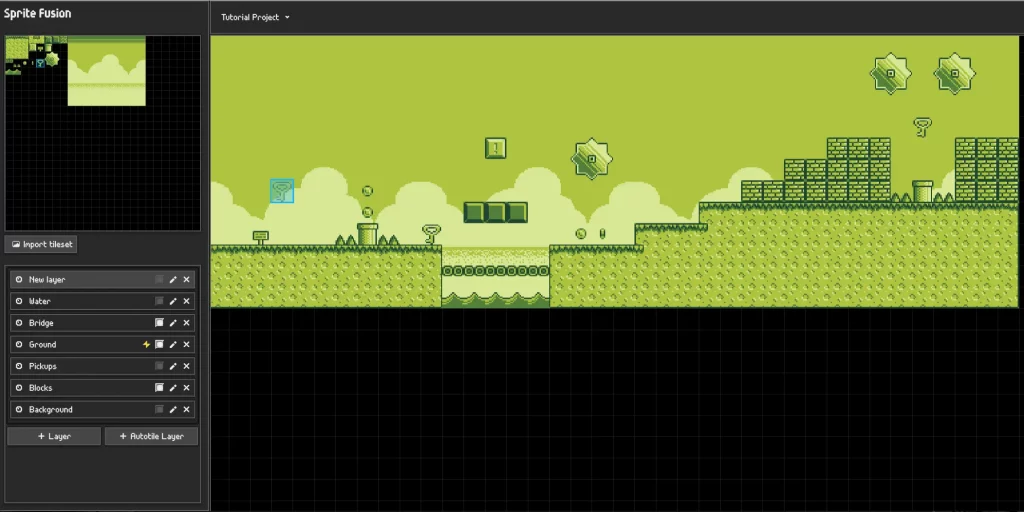
Pour ceux qui souhaitent partager leurs projets avec d’autres, Sprite Fusion permet également d’exporter vos projets au format JSON compact, facilitant ainsi le partage. Avec des exemples tels que Hazmat Pixel Art – Niveau 1, Mining Odyssey, Spritesheet Dashers et Tiled Map Retro Simulator, vous pouvez voir l’étendue des possibilités offertes par cet outil.
L’utilisation de cet éditeur est totalement gratuite et ne nécessite aucune création de compte. Il fonctionne avec les principaux navigateurs et vous pouvez l’utiliser sans aucune limitation pour un usage personnel ou commercial. Et si vous avez des questions, n’hésitez pas à les poser sur leur serveur Discord .
Spite Fusion prend également en charge les collisions, vous permettant de définir n’importe quelle couche en tant que collisionneur pour utiliser les collisions dans votre jeu. De plus, il propose une fonctionnalité d’auto-tiling, qui vous permet de placer automatiquement des tuiles en fonction de leurs voisines, facilitant ainsi la conception rapide de cartes de terrain.
A vous de tester maintenant !
Merci à Lorenper