-
chevron_right
Pirated Movies Flood YouTube, Millions of Views on Compromised Channels
news.movim.eu / TorrentFreak · 5 days ago - 20:09 · 5 minutes
 It’s Tuesday, April 24, 2007, and other than Beyoncé & Shakira singing
Beautiful Liar
on the radio, nothing much is happening.
It’s Tuesday, April 24, 2007, and other than Beyoncé & Shakira singing
Beautiful Liar
on the radio, nothing much is happening.
For someone called haroldlky , whose real identity is currently unknown, at least part of that day was spent opening a channel on YouTube, a video site that was yet to celebrate its second birthday.
On that day more than 17 years ago, the fledgling YouTuber uploaded three videos that appear to have an engineering theme. The total running time for the trio, a modest 42 seconds.
Whether ‘haroldlky’ was content with less than 400 views in total over the next 17 years, or whether he even visited YouTube ever again, is completely unknown. If he visited today, he might be a little surprised.
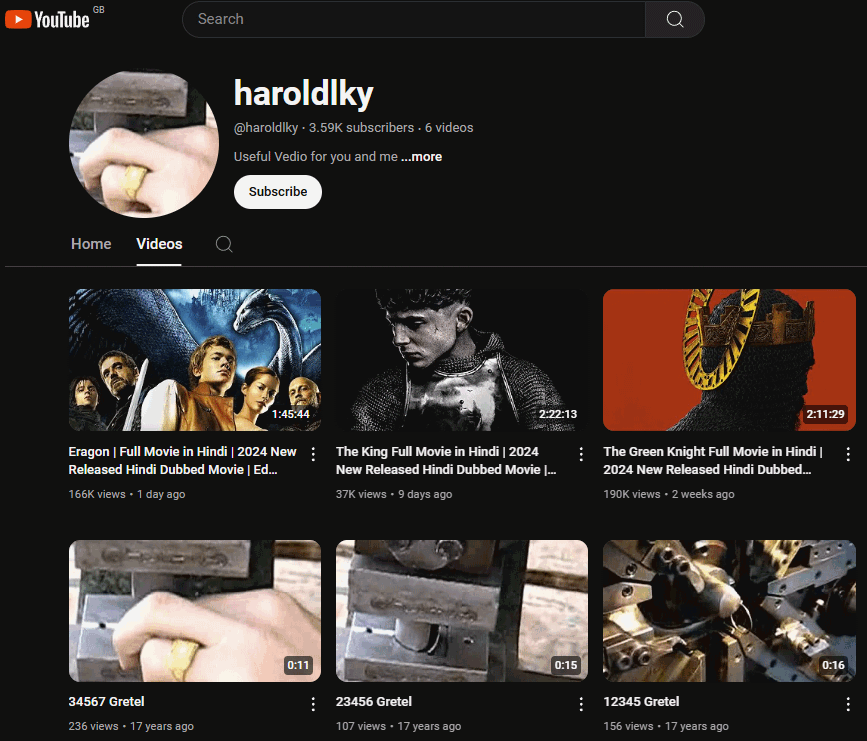
After suddenly bursting back to life two weeks ago, three new videos were uploaded to his channel. All of these uploads were movies (Eragon, The King, and The Green Knight) dubbed in Hindi, and have since been viewed 376,000 times.
No Isolated Incident
After receiving a tip this morning that something unusual may be playing out on YouTube, we took a closer look. Similar events to that outlined above may have happened before but, roughly two weeks ago, the pace appears to have quickened and may have further increased during the past few days.
Many of the channels currently offering pirated movies appear to be personal accounts that may have been compromised. That’s unlikely to mean an issue at YouTube but rather some kind of data breach on another platform, which typically lead to exploitation of users’ duplication of login credentials across various services.
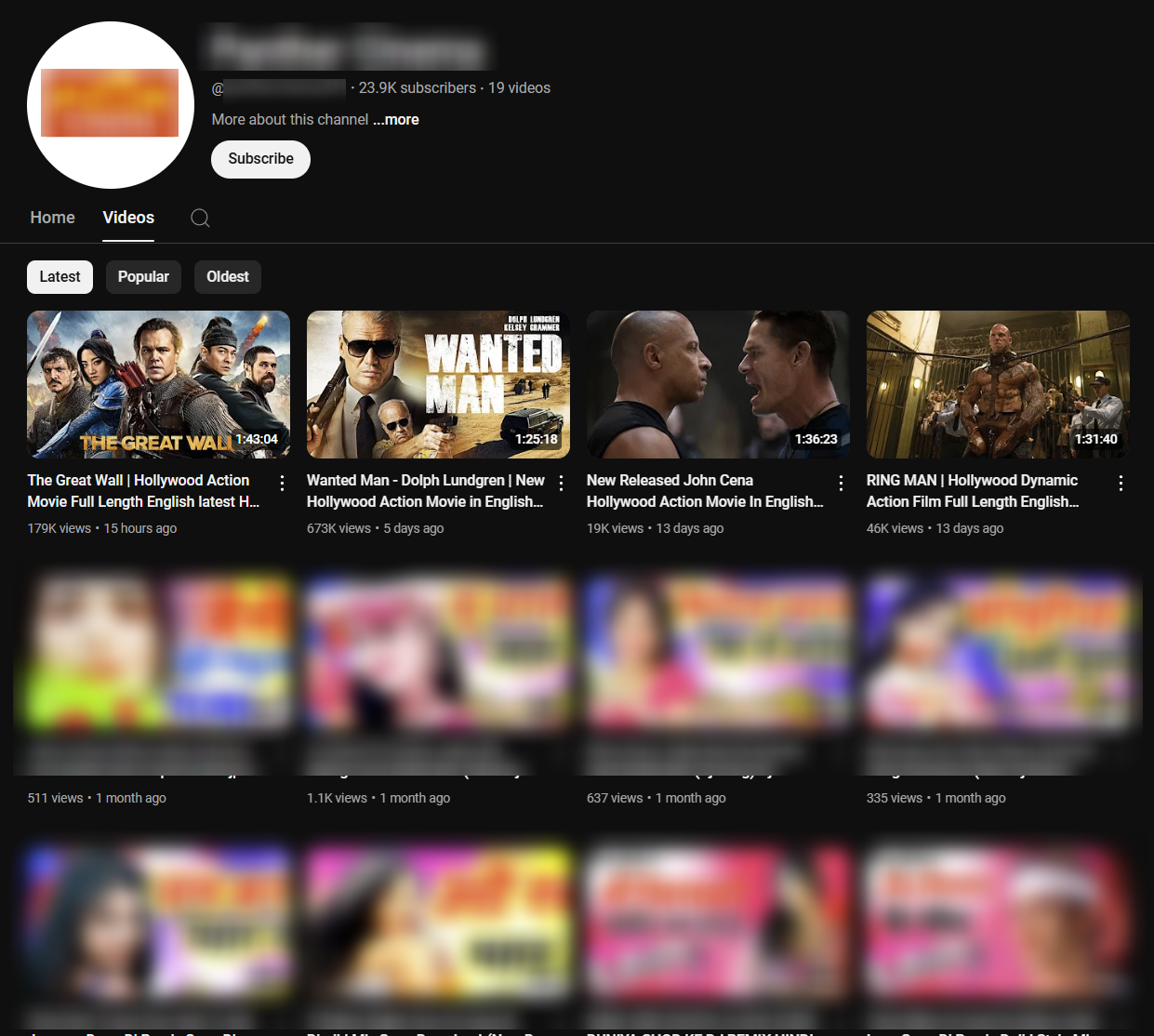
(Note: where channels relate to regular citizens and have been used recently, or contain home movies with families and friends, we have redacted information to limit identification of these potential victims)
We have no specific knowledge of the mechanism through which credentials may have been obtained, if indeed that’s the case here. However, if we look at events from the opposite direction, it seems unlikely that a YouTuber uploading math tutorials receiving a few hundred views (above) would suddenly switch to Hollywood blockbusters overnight.
In less than two weeks, these rogue uploads have already been viewed 917K times.
Bigger Movies, Bigger Numbers
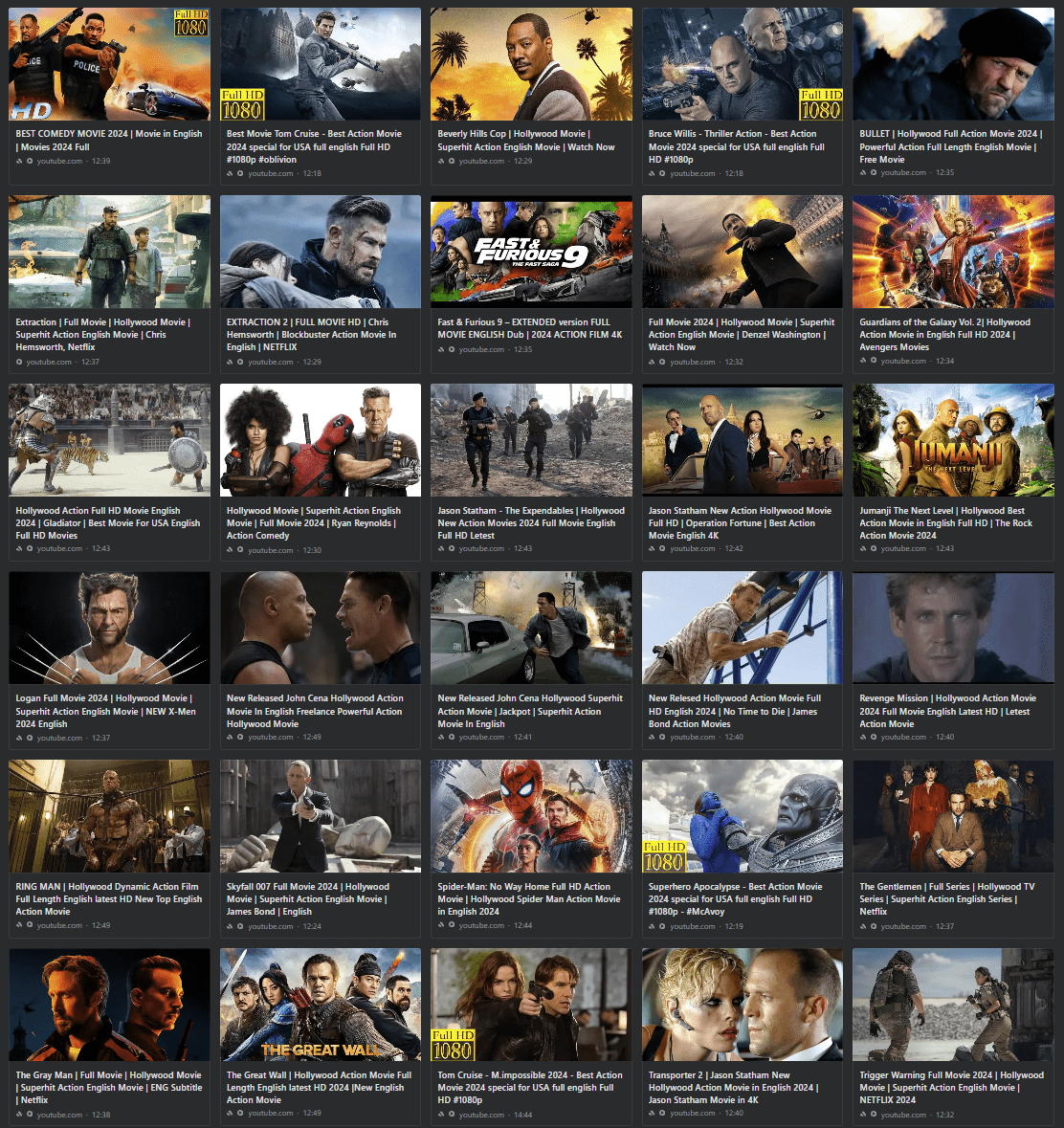
It would be impossible for us to document every channel affected, but there are a few that catch the eye. Some channels may have been created in advance for use in nefarious activities. In most cases, however, it’s difficult to determine intent based on scant information. Out of caution, screenshots are partly redacted.
The pair of images below show that channel creation dates can differ wildly. On the left is a channel with 117K subscribers and just seven videos, displaying a join date of September 17, 2023. The pirated films uploaded to the channel are responsible for most of the 7.4 million views generated in the last 10 days.
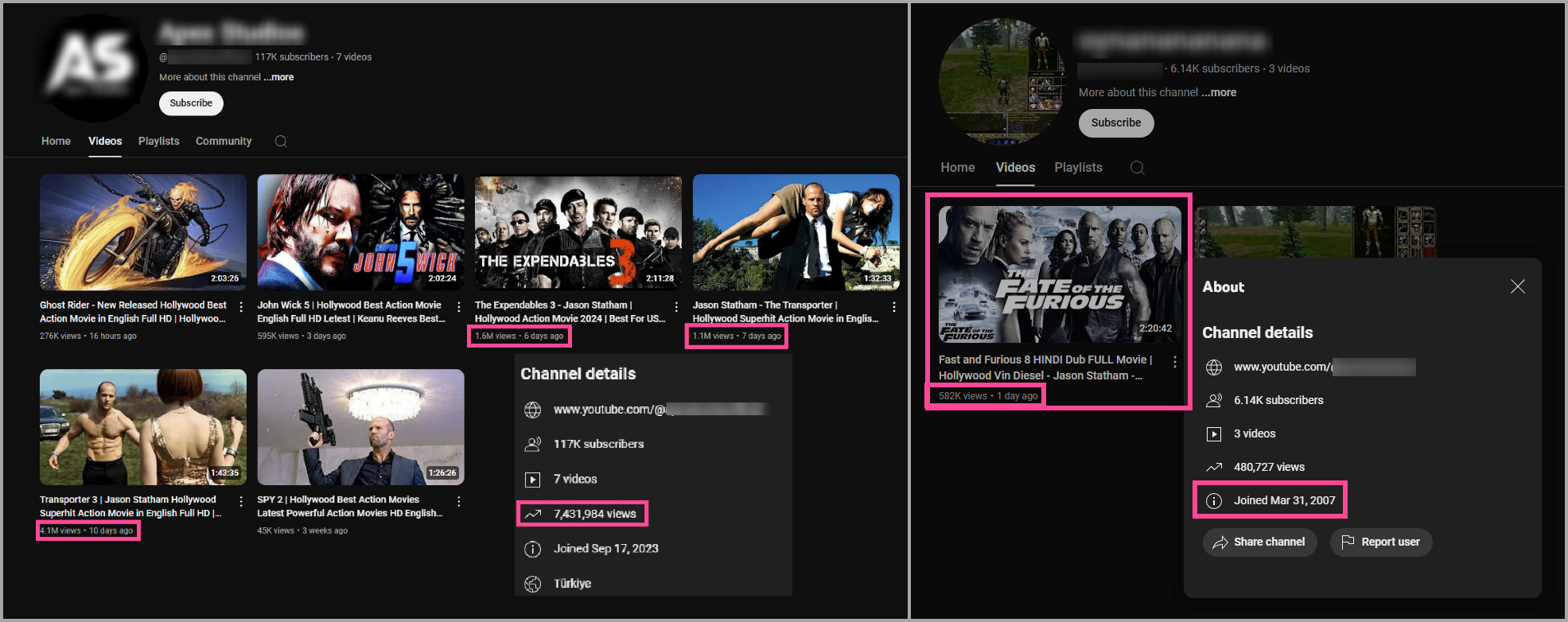
On the right is a channel with just three videos, 6.1K subscribers, and an ancient join date of March 31, 2007. Just one pirated movie, Fate of the Furious, has already been viewed 582K times since it was uploaded yesterday.
Who, Why, and How is It Possible?
Who might be behind such a significant effort to spread so many movies is too early to say. We assume there’s no way of making money from these uploads, at least not on YouTube, so at least potentially, money may not be a factor*.
Update: No surprises, money is the main factor, see explanation below
Judging purely on outward impressions, various presentational factors, and the nature of those commenting on these movies, it seems likely that there’s at least some connection to India. Inbound links to the movies may be of interest to YouTube, but at least initially, a bigger question may be the focus.
For reasons unknown and with no outward indication of video tampering, these movie uploads appear to have completely circumvented Content ID, YouTube’s anti-piracy fingerprinting system. While that can happen for older titles or those already in the system, one would assume every angle would be covered for new and recent movies.
It’s feasible that fingerprints aren’t being supplied or maybe some glitch in the matrix is responsible. Interestingly, an upload of the Netflix series ‘The Gentlemen’ (every episode, running time 6h 23m) shows something that suggests it may have been subjected to scanning.
As seen in the image below, a music track by ‘Zoxer’ titled ‘Forward’ is listed as making an appearance in the series.
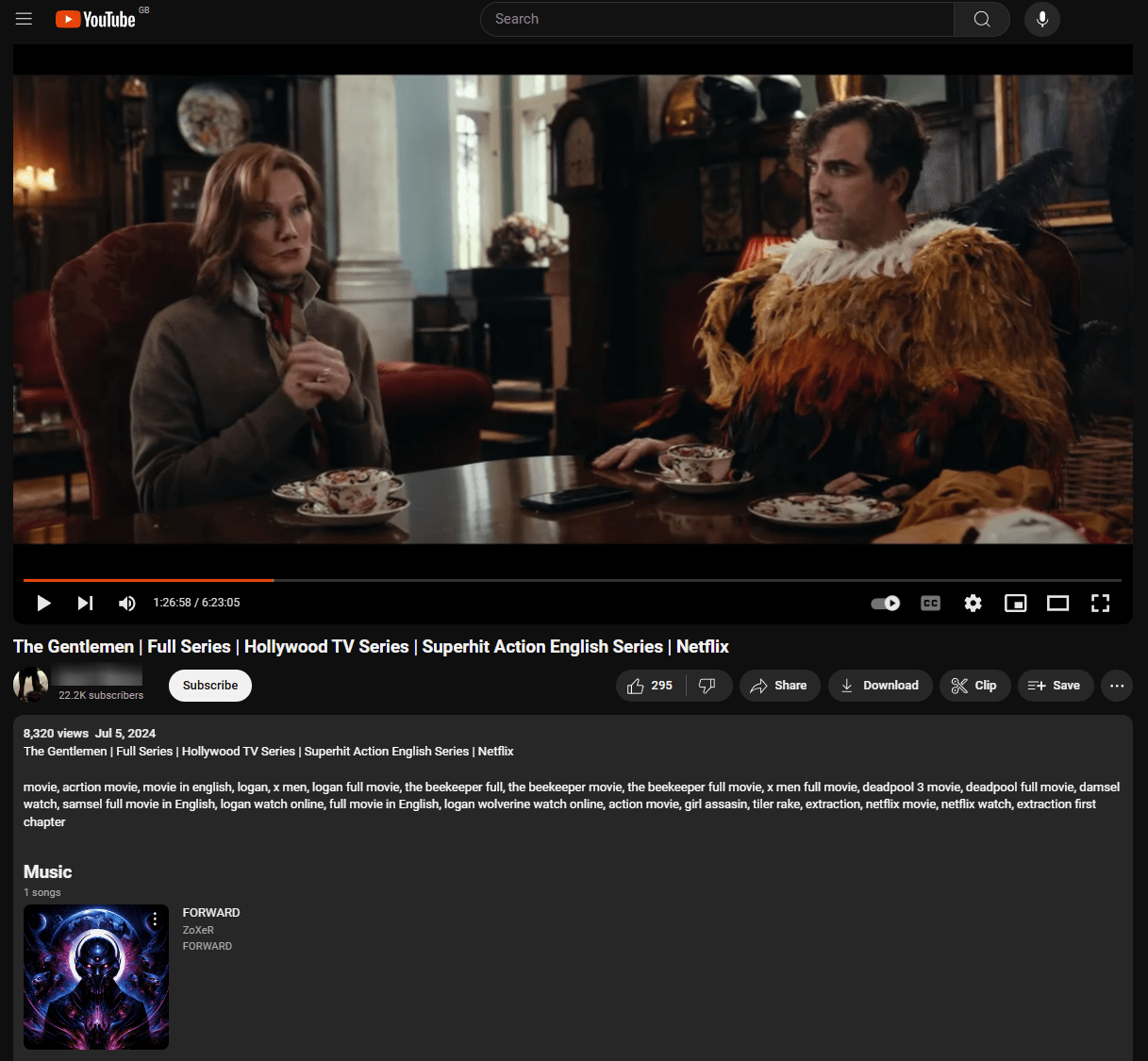
If this was indeed a content match and not something manually entered by the uploader, it seems unusual that the rest of the tracks in the series weren’t identified in the same way. Our searches found no record of ‘Forward’ by Zoxer appearing in the series; it may have done, we’ve just had no luck finding it.
Update and explanation: It appears that the audio content matches on these movies do not rely on the allegedly-infringed tracks being in the movie, only that they’re present in the video files uploaded to YouTube. The scheme apparently works something like this:
1. Create or otherwise obtain tracks that are not detected by Content ID
2. Register those tracks (illegally) with Distrokid, CD Baby, or Tunecore (who are oblivious to the fraud)
3. Obtain a movie that will get lots of views
4. Use software to stitch the audio track to the end of the movie
5. Upload resulting video file to YouTube
6. Wait for a content match on the music, monetize the entire video
7. Get paid a small amount, or nothing at all if the royalty collection companies find out
Those enjoying the uploaded movies appear to have no problem finding them as they’re racking up millions of views. It’s hard to say exactly how many millions of views overall, but it’s a significant number, especially when in normal circumstances the figure wouldn’t be worth reporting.
There’s no requirement for YouTube to be proactive in these circumstances, but why nobody has reported the haul below, which represents just a few of the movies uploaded, is certainly interesting.
From: TF , for the latest news on copyright battles, piracy and more.









{kind=link}
{kind=link}
{kind=link}